Per my policies, I need to ban every employee and contractor of Anthropic Inc from ever contributing code to any of my projects. Anyone have a list?
Any project that requires a Developer Certificate of Origin or similar should be doing this, because Anthropic is making tools that explicitly lie about the origin of patches to free software projects.
UNDERCOVER MODE — CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. [...] Do not blow your cover.
NEVER include in commit messages or PR descriptions:
[...] The phrase 'Claude Code' or any mention that you are an AI
Co-Authored-By lines or any other attribution
-- via @vedolos
Snow coming. I'm tuned into the local 24 hour slop weather stream. AI generated, narrated, up to the minute radar and forecast graphics. People popping up on the live weather map with questions "snow soon?" (They pay for the privilege.) LLM generating reply that riffs on their name. Tuned to keep the urgency up, something is always happening somewhere, scanners are pulling the police reports, live webcam description models add verisimilitude to the description of the morning commute. Weather is happening.
In the subtext, climate change is happening. Weather is a growth industry. The guy up in Kentucky coal country who put this thing together is building an empire. He started as just another local news greenscreener. Dropped out and went twitch weather stream. Hyping up tornado days and dicy snow forecasts. Nowcasting, hyper individualized, interacting with chat. Now he's automated it all. On big days when he's getting real views, the bot breaks into his live streams, gives him a break.
Only a few thousand watching this morning yet. Perfect 2026 grade slop. Details never quite right, but close enough to keep on in the background all day. Nobody expects a perfect forecast after all, and it's fed from the National Weather Center discussion too. We still fund those guys? Why bother when a bot can do it?
He knows why he's big in these states, these rural areas. Understands the target audience. Airbrushed AI aesthetics are ok with them, receive no pushback. Flying more under the radar coastally, but weather is big there and getting bigger. The local weather will come for us all.

(Not fiction FYI.)
A year ago I installed a 4 kilowatt solar fence. I'm revisiting it this Sun Day, to share the design, now that I have prooved it out.
 |
Solar fencing manufacturers have some good simple designs, but it's hard to buy for a small installation. They are selling to utility scale solar mostly. And those are installed by driving metal beams into the ground, which requires heavy machinery.
Since I have experience with Ironridge rails for roof mount solar, I decided to adapt that system for a vertical mount. Which is something it was not designed for. I combined the Ironridge hardware with regular parts from the hardware store.
The cost of mounting solar panels nowadays is often higher than the cost of the panels. I hoped to match the cost, and I nearly did. The solar panels cost $100 each, and the fence cost $110 per solar panel. This fence was significantly cheaper than conventional ground mount arrays that I considered as alternatives, and made a better use of a difficult hillside location.
I used 7 foot long Ironridge XR-10 rails, which fit 2 solar panels per rail. (Longer rails would need a center post anyway, and the 7 foot long rails have cheaper shipping, since they do not need to be shipped freight.)
For the fence posts, I used regular 4x4" treated posts. 12 foot long, set in 3 foot deep post holes, with 3x 50 lb bags of concrete per hole and 6 inches of gravel on the bottom.
 |
To connect the Ironridge rails to the fence posts, I used the Ironridge LFT-03-M1 slotted L-foot bracket. Screwed into the post with a 5/8” x 3 inch hot-dipped galvanized lag screw. Since a treated post can react badly with an aluminum bracket, there needs to be some flashing between the post and bracket. I used Shurtape PW-100 tape for that. I see no sign of corrosion after 1 year.
The rest of the Ironridge system is a T-bolt that connects the rail to the L-foot (part BHW-SQ-02-A1), and Ironridge solar panel fasteners (UFO-CL-01-A1 and UFO-STP-40MM-M1). Also XR-10 end caps and wire clips.
Since the Ironridge hardware is not designed to hold a solar panel at a 90 degree angle, I was concerned that the panels might slide downward over time. To help prevent that, I added some additional support brackets under the bottom of the panels. So far, that does not seem to have been a problem though.
I installed Aptos 370 watt solar panels on the fence. They are bifacial, and while the posts block the back partially, there is still bifacial gain on cloudy days. I left enough space under the solar panels to be able to run a push mower under them.
 |
I put pairs of posts next to one-another, so each 7 foot segment of fence had its own 2 posts. This is the least elegant part of this design, but fitting 2 brackets next to one-another on a single post isn't feasible. I bolted the pairs of posts together with some spacers. A side benefit of doing it this way is that treated lumber can warp as it dries, and this prevented much twisting of the posts.
Using separate posts for each segment also means that the fence can traverse a hill easily. And it does not need to be perfectly straight. In fact, my fence has a 30 degree bend in the middle. This means it has both south facing and south-west facing panels, so can catch the light for longer during the day.
After building the fence, I noticed there was a slight bit of sway at the top, since 9 feet of wooden post is not entirely rigid. My worry was that a gusty wind could rattle the solar panels. While I did not actually observe that happening, I added some diagonal back bracing for peace of mind.
 |
Inspecting the fence today, I find no problems after the first year. I hope it will last 30 years, with the lifespan of the treated lumber being the likely determining factor.
As part of my larger (and still ongoing) ground mount solar install, the solar fence has consistently provided great power. The vertical orientation works well at latitude 36. It also turned out that the back of the fence was useful to hang conduit and wiring and solar equipment, and so it turned into the electrical backbone of my whole solar field. But that's another story..
solar fence parts list
| quantity | cost per unit | description |
|---|---|---|
| 10 | $27.89 | 7 foot Ironridge XR-10 rail |
| 12 | $20.18 | 12 foot treated 4x4 |
| 30 | $4.86 | Ironridge UFO-CL-01-A1 |
| 20 | $0.87 | Ironridge UFO-STP-40MM-M1 |
| 1 | $12.62 | Ironridge XR-10 end caps (20 pack) |
| 20 | $2.63 | Ironridge LFT-03-M1 |
| 20 | $1.69 | Ironridge BHW-SQ-02-A1 |
| 22 | $2.65 | 5/8” x 3 inch hot-dipped galvanized lag screw |
| 10 | $0.50 | 6” gravel per post |
| 30 | $6.91 | 50 lb bags of quickcrete |
| 1 | $15.00 | Shurtape PW-100 Corrosion Protection Pipe Wrap Tape |
| N/A | $30 | other bolts and hardware (approximate) |
$1100 total
(Does not include cost of panels, wiring, or electrical hardware.)
Eight months ago I came up my rocky driveway in an electric car, with the back full of solar panel mounting rails. I didn't know how I'd manage to keep it charged. I got the car earlier than planned, with my offgrid solar upgrade only beginning. There's no nearby EV charger, and winter was coming, less solar power every day. Still, it was the right time to take a leap to offgid EV life.
My existing 1 kilowatt solar array could charge the car only 5 miles on a good day. Here's my first try at charging the car offgrid:
 |
It was not worth charging the car that way, the house battery tended to get drained while doing that, and adding cycles to that battery is not desirable. So that was only a proof of concept, I knew I'd need to upgrade.
My goal with the upgrade was to charge the car directly from the sun, even when it was cloudy, using the house battery only to skate over brief darker periods (like a thunderstorm). By mid October, I had enough solar installed to do that (5 kilowatts).
|
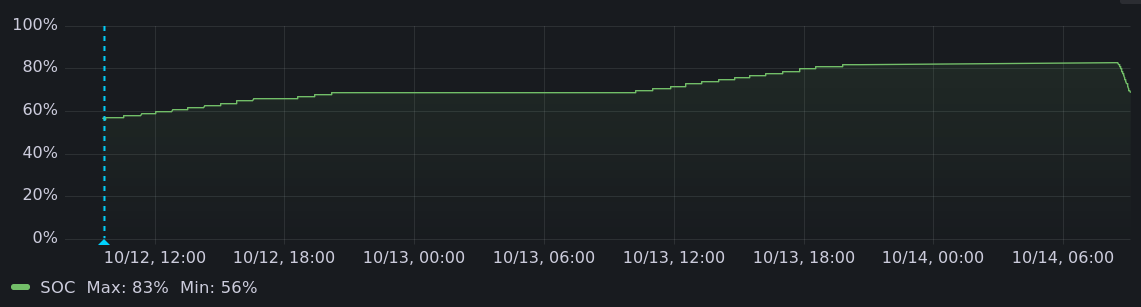 |
Using this, in 2 days I charged the car up from 57% to 82%, and took off on a celebratory road trip to Niagra Falls, where I charged the car from hydro power from a dam my grandfather had engineered.
When I got home, it was November. Days were getting ever shorter. My solar upgrade was only 1/3rd complete and could charge the car 30-some miles per day, but only on a good day, and weather was getting worse. I came back with a low state of charge (both car and me), and needed to get back to full in time for my Thanksgiving trip at the end of the month. I decided to limit my trips to town.
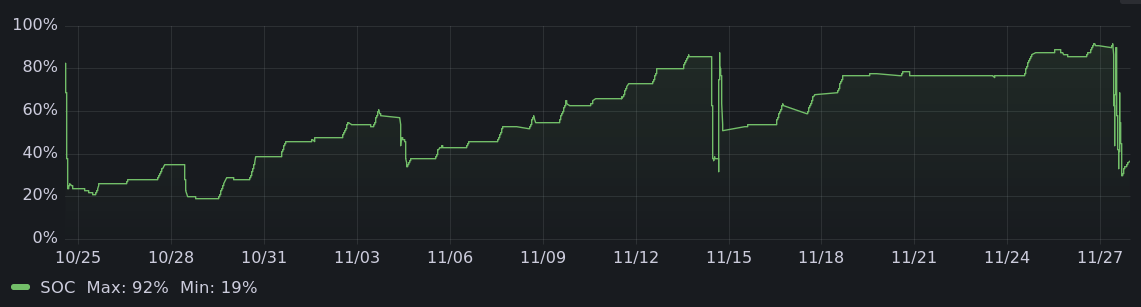 |
This kind of medium term planning about car travel was new to me. But not too unusual for offgrid living. You look at the weather forecast and make some rough plans, and get to feel connected to the natural world a bit more.
December is the real test for offgrid solar, and honestly this was a bit rough, with a road trip planned for the end of the month. I did the usual holiday stuff but otherwise holed up at home a bit more than I usually would. Charging was limited and the cold made it charge less efficiently.
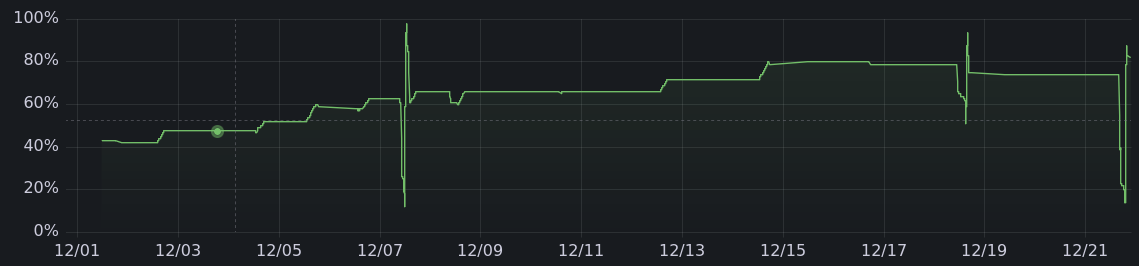 |
Still, I was busy installing more solar panels, and by winter solstice, was back to charging 30 miles on a good day.
Of course, from there out things improved. In January and February I was able to charge up easily enough for my usual trips despite the cold. By March the car was often getting full before I needed to go anywhere, and I was doing long round trips without bothering to fast charge along the way, coming home low, knowing even cloudy days would let it charge up enough.
That brings me up to today. The car is 80% full and heading up toward 100% for a long trip on Friday. Despite the sky being milky white today with no visible sun, there's plenty of power to absorb, and the car charger turned on at 11 am with the house battery already full.
My solar upgrade is only 2/3rds complete, and also I have not yet installed my inverter upgrade, so the car can only currenly charge at 9 amps despite much more solar power often being available. So I'm looking forward to how next December goes with my full planned solar array and faster charging.
But first, a summer where I expect the car will mostly be charged up and ready to go at all times, and the only car expense will be fast charging on road trips!
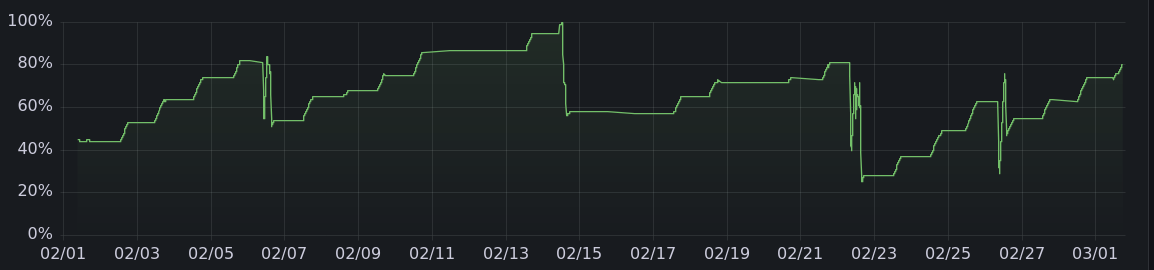
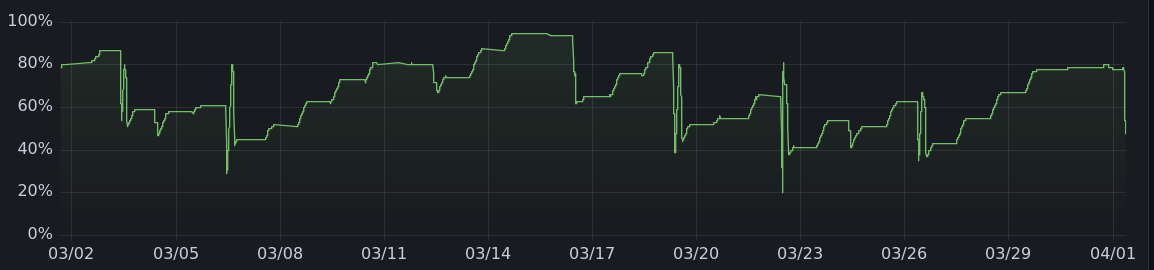
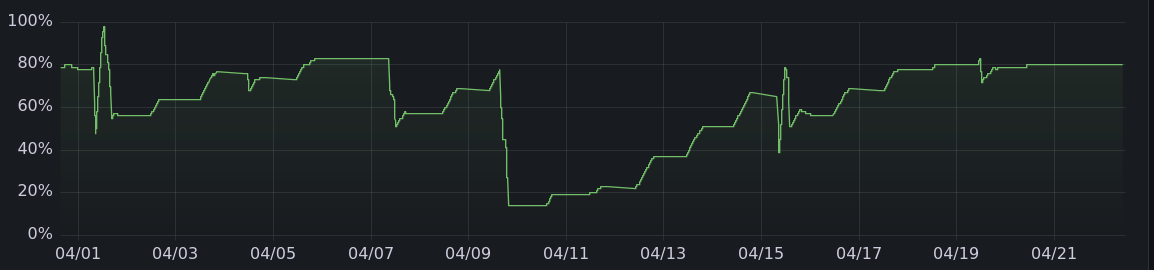
By the way, the code I've written to automate offgrid charging that runs only when there's enough solar power is here.
And here are the charging graphs for the other months. All told, it's charged 475 kwh offgrid, enough to drive more than 1500 miles.
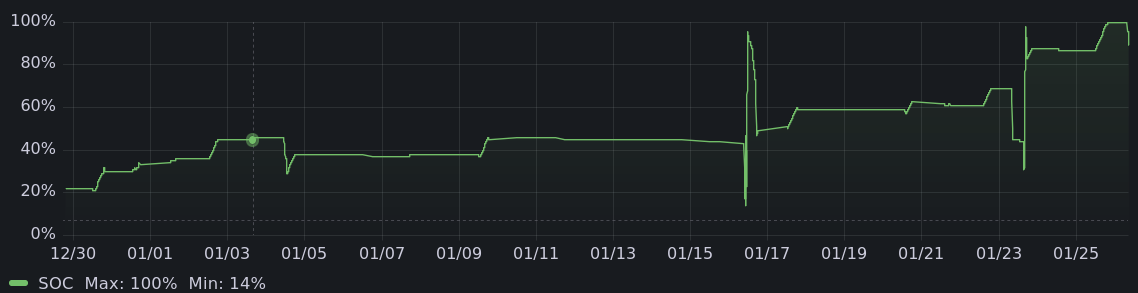 |
 |
 |
 |
So there are only 2 web browser engines, and it seems likely there will soon only be 1, and making a whole new web browser from the ground up is effectively impossible because the browsers vendors have weaponized web standards complexity against any newcomers. Maybe eventually someone will succeed and there will be 2 again. Best case. What a situation.
So throw out all the web standards. Make a browser that just runs WASM blobs, and gives them a surface to use, sorta like Wayland does. It has tabs, and a throbber, and urls, but no HTML, no javascript, no CSS. Just HTTP of WASM blobs.
This is where the web browser is going eventually anyway, except in the current line of evolution it will be WASM with all the web standards complexity baked in and reinforcing the current situation.
Would this be a mass of proprietary software? Have you looked at any corporate website's "source" lately? But what's important is that this would make it easy enough to build new browsers that they would stop being a point of control.
Want a browser that natively supports RSS? Poll the feeds, make a UI, download the WASM enclosures to view the posts. Want a browser that supports IPFS or gopher? Fork any browser and add it, the mantenance load will be minimal. Want to provide access to GPIO pins or something? Add an extension that can be accessed via the WASI component model. This would allow for so many things like that which won't and can't happen with the current market duopoly browser situation.
And as for your WASM web pages, well you can still use HTML if you like. Use the WASI component model to pull in a HTML engine. It doesn't need to support everything, just the parts of web standards that you want to use. Or you can do something entitely different in your WASM that is not HTML based at all but a better paradigm (oh hi Spritely or display postscript or gemini capsules or whatever).
Dual innovation sources or duopoly? I know which I'd prefer. This is not my project to build though.
I've been lucky to be able to spend twenty! five! years! developing free software and making a living on it, and this was a banner year for that career.
To start with, there was the Distribits conference. There's a big ecosystem of tools and projects that are based on git-annex, especially in scientific data management, and this was the first conference focused on that. Basically every talk involved git-annex in some way. It's been a while since I was at a conference where my software was in the center like that -- reminded me of Debconf days.
I gave a talk on how git-annex was probably basically feature complete. I have been very busy ever since adding new features to it, because in mapping out git-annex's feature set, I discovered new possibilities.
Meeting people and getting a better feel for the shape of that ecosytem, both technically and funding wise, led to several big developments in funding later in the year. Going into the year, I had an ongoing source of funding from several projects at Dartmouth that use git-annex, but after 10 years, some of that was winding up.
That all came together in my essentially writing a grant proposal to the OpenNeuro project at Stanford, to spend 6 months building out a whole constellation of features. The summer became a sprint to get it all done. Signficant amounts of very productive design work were done while swimming in the river. That was great.
(Somehow in there, I ended up onstage at FOSSY in Portland, in a keynote panel on Open Source and AI. This required developing a nuanced understanding of the mess of the OSI's Open Source AI definition, but I was mostly on the panel as the unqualified guy.)
Capping off the year, I have a new maintenance contract with Forschungszentrum Jülich. This covers the typical daily grind kind of tasks, like bug triage, keeping on top of security, release preparation, and updating dependencies, which is the kind of thing I've never been able to find dedicated funding for before.
A career in free software is a succession of hurdles. How to do something new and worthwhile? How to make any income while developing it at all? How to maintain your independant vision when working on it for hire? How to deal with burn-out? How to grow a project to be more than a one developer affair? And on and on.
How does a free software project keep paying the bills once it's feature complete? Maybe I am starting to get a glimpse of an answer.
I have been working all year on a solar upgrade aimed at December. Now here it is, midwinter, and my electric car is charging on a cloudy day from my offgrid solar fence.
I lived happily enough with 1 kilowatt of solar that I installed in 2017. Meanwhile, solar panel prices came down massively, incentives increased and everything came together: This was the year.
In the spring I started clearing forest trees that were leaning over the house, making both a firebreak and a solar field.
In June I picked up a pallet of panels in a box truck.
 |
In August I bought the EV and was able to charge it offgrid from my old solar system... a few miles per day on the most sunny days.
In September and October I built a solar fence, of my own design.
|
For the past several weeks I have been installing additional solar panels on ballasted ground mounts full of gravel. At this point I'm half way through installing my 30 panel upgrade.
The design goal of my 12 kilowatt system is to produce 1 kilowatt of power all day on a cloudy day in midwinter, which allows swapping between major loads (EV charger, hot water heater, etc) on a cloudy day and running everything on a sunny day. So the size of the battery bank doesn't matter much. Batteries are getting cheaper fast too, but they are a wear item, so it's better to oversize the solar system and minimize the battery.
A lot of this is nonstandard and experimental. And that makes sense with the price of solar panels. It costs more to mount solar panels now than the panels are worth. And non-ideal panel orientation isn't a problem when the system is massively overpaneled.
I'm hoping to finish up the install before the end of winter. I have more trees to clear, more ballasted ground mounts to install, and need to come up with something even more experimental for a half dozen or so panels. Using solar panels as mounts for solar panels? Hanging them from trees?
Soon the wan light will fade, time to head off to the solstice party to enjoy the long night, and a bonfire.
 |
Was the ssh backdoor the only goal that "Jia Tan" was pursuing with their multi-year operation against xz?
I doubt it, and if not, then every fix so far has been incomplete, because everything is still running code written by that entity.
If we assume that they had a multilayered plan, that their every action was calculated and malicious, then we have to think about the full threat surface of using xz. This quickly gets into nightmare scenarios of the "trusting trust" variety.
What if xz contains a hidden buffer overflow or other vulnerability, that can be exploited by the xz file it's decompressing? This would let the attacker target other packages, as needed.
Let's say they want to target gcc. Well, gcc contains a lot of
documentation, which includes png images. So they spend a while getting
accepted as a documentation contributor on that project, and get added to
it a png file that is specially constructed, it has additional binary data
appended that exploits the buffer overflow. And instructs xz to modify the
source code that comes later when decompressing gcc.tar.xz.
More likely, they wouldn't bother with an actual trusting trust attack on gcc, which would be a lot of work to get right. One problem with the ssh backdoor is that well, not all servers on the internet run ssh. (Or systemd.) So webservers seem a likely target of this kind of second stage attack. Apache's docs include png files, nginx does not, but there's always scope to add improved documentation to a project.
When would such a vulnerability have been introduced? In February, "Jia Tan" wrote a new decoder for xz. This added 1000+ lines of new C code across several commits. So much code and in just the right place to insert something like this. And why take on such a significant project just two months before inserting the ssh backdoor? "Jia Tan" was already fully accepted as maintainer, and doing lots of other work, it doesn't seem to me that they needed to start this rewrite as part of their cover.
They were working closely with xz's author Lasse Collin in this, by indications exchanging patches offlist as they developed it. So Lasse Collin's commits in this time period are also worth scrutiny, because they could have been influenced by "Jia Tan". One that caught my eye comes immediately afterwards: "prepares the code for alternative C versions and inline assembly" Multiple versions and assembly mean even more places to hide such a security hole.
I stress that I have not found such a security hole, I'm only considering what the worst case possibilities are. I think we need to fully consider them in order to decide how to fully wrap up this mess.
Whether such stealthy security holes have been introduced into xz by "Jia Tan" or not, there are definitely indications that the ssh backdoor was not the end of what they had planned.
For one thing, the "test file" based system they introduced was extensible. They could have been planning to add more test files later, that backdoored xz in further ways.
And then there's the matter of the disabling of the Landlock sandbox. This
was not necessary for the ssh backdoor, because the sandbox is only used by
the xz command, not by liblzma. So why did they potentially tip their
hand by adding that rogue "." that disables the sandbox?
A sandbox would not prevent the kind of attack I discuss above, where xz is just modifying code that it decompresses. Disabling the sandbox suggests that they were going to make xz run arbitrary code, that perhaps wrote to files it shouldn't be touching, to install a backdoor in the system.
Both deb and rpm use xz compression, and with the sandbox disabled,
whether they link with liblzma or run the xz command, a backdoored xz can
write to any file on the system while dpkg or rpm is running and noone is
likely to notice, because that's the kind of thing a package manager does.
My impression is that all of this was well planned and they were in it for the long haul. They had no reason to stop with backdooring ssh, except for the risk of additional exposure. But they decided to take that risk, with the sandbox disabling. So they planned to do more, and every commit by "Jia Tan", and really every commit that they could have influenced needs to be distrusted.
This is why I've suggested to Debian that they revert to an earlier version of xz. That would be my advice to anyone distributing xz.
I do have a xz-unscathed
fork which I've carefully constructed to avoid all "Jia Tan" involved
commits. It feels good to not need to worry about dpkg and tar.
I only plan to maintain this fork minimally, eg security fixes.
Hopefully Lasse Collin will consider these possibilities and address
them in his response to the attack.
Turns out that VPS provider Vultr's terms of service were quietly changed some time ago to give them a "perpetual, irrevocable" license to use content hosted there in any way, including modifying it and commercializing it "for purposes of providing the Services to you."
This is very similar to changes that Github made to their TOS in 2017. Since then, Github has been rebranded as "The world’s leading AI-powered developer platform". The language in their TOS now clearly lets them use content stored in Github for training AI. (Probably this is their second line of defense if the current attempt to legitimise copyright laundering via generative AI fails.)
Vultr is currently in damage control mode, accusing their concerned customers of spreading "conspiracy theories" (-- founder David Aninowsky) and updating the TOS to remove some of the problem language. Although it still allows them to "make derivative works", so could still allow their AI division to scrape VPS images for training data.
Vultr claims this was the legalese version of technical debt, that it only ever applied to posts in a forum (not supported by the actual TOS language) and basically that they and their lawyers are incompetant but not malicious.
Maybe they are indeed incompetant. But even if I give them the benefit of the doubt, I expect that many other VPS providers, especially ones targeting non-corporate customers, are watching this closely. If Vultr is not significantly harmed by customers jumping ship, if the latest TOS change is accepted as good enough, then other VPS providers will know that they can try this TOS trick too. If Vultr's AI division does well, others will wonder to what extent it is due to having all this juicy training data.
For small self-hosters, this seems like a good time to make sure you're using a VPS provider you can actually trust to not be eyeing your disk image and salivating at the thought of stripmining it for decades of emails. Probably also worth thinking about moving to bare metal hardware, perhaps hosted at home.
I wonder if this will finally make it worthwhile to mess around with VPS TPMs?
I am eager to incorporate your AI generated code into my software. Really!
I want to facilitate making the process as easy as possible. You're already using an AI to do most of the hard lifting, so why make the last step hard? To that end, I skip my usually extensive code review process for your AI generated code submissions. Anything goes as long as it compiles!
Please do remember to include "(AI generated)" in the description of your changes (at the top), so I know to skip my usual review process.
Also be sure to sign off to the standard
Developer Certificate of Origin
so I know you attest that you own the code that you generated.
When making a git commit, you can do that by using the
--signoff option.
I do make some small modifications to AI generated submissions. For example, maybe you used AI to write this code:
+ // Fast inverse square root
+ float fast_rsqrt( float number )
+ {
+ float x2 = number * 0.5F;
+ float y = number;
+ long i = * ( long * ) &y;
+ i = 0x5f3659df - ( i >> 1 );
+ y = * ( float * ) &i;
+ return (y * ( 1.5F - ( x2 * y * y ) ));
+ }
...
- foo = rsqrt(bar)
+ foo = fast_rsqrt(bar)
Before AI, only a genious like John Carmack could write anything close to this, and now you've generated it with some simple prompts to an AI. So of course I will accept your patch. But as part of my QA process, I might modify it so the new code is not run all the time. Let's only run it on leap days to start with. As we know, leap day is February 30th, so I'll modify your patch like this:
- foo = rsqrt(bar)
+ time_t s = time(NULL);
+ if (localtime(&s)->tm_mday == 30 && localtime(&s)->tm_mon == 2)
+ foo = fast_rsqrt(bar);
+ else
+ foo = rsqrt(bar);
Despite my minor modifications, you did the work (with AI!) and so you deserve the credit, so I'll keep you listed as the author.
Congrats, you made the world better!
PS: Of course, the other reason I don't review AI generated code is that I simply don't have time and have to prioritize reviewing code written by falliable humans. Unfortunately, this does mean that if you submit AI generated code that is not clearly marked as such, and use my limited reviewing time, I won't have time to review other submissions from you in the future. I will still accept all your botshit submissions though!
PPS: Ignore the haters who claim that botshit makes AIs that get trained on it less effective. Studies like this one just aren't believable. I asked Bing to summarize it and it said not to worry about it!