Joey at some point blogged about his work here on a semi-daily basis. For lower post frequency and wider-interest topics, see the main blog.
Since propellor is configured by writing Haskell, type errors are an important part of its interface. As more type level machinery has been added to propellor, it's become more common for type errors to refer to hard to understand constraints. And sometimes simple mistakes in a propellor config result in the type checker getting confused and spewing an error that is thousands of lines of gobbledygook.
Yesterday's release of the new type-errors library got me excited to improve propellor's type errors.
Most of the early wins came from using ghc's TypeError class, not the new library. I wanted custom type errors that were able to talk about problems with Property targets, like these:
• ensureProperty inner Property is missing support for:
FreeBSD
• This use of tightenTargets would widen, not narrow, adding:
ArchLinux + FreeBSD
• Cannot combine properties:
Property FreeBSD
Property HasInfo + Debian + Buntish + ArchLinux
So I wrote a type-level pretty-printer for propellor's MetaType lists. One
interesting thing about it is that it rewrites types such as Targeting
OSDebian back to the Debian type alias that the user expects to see.
To generate the first error message above, I used the pretty-printer like this:
(TypeError
('Text "ensureProperty inner Property is missing support for: "
':$$: PrettyPrintMetaTypes (Difference (Targets outer) (Targets inner))
)
)
Often a property constructor in propellor gets a new argument added to it. A propellor config that has not been updated to include the new argument used to result in this kind of enormous and useless error message:
• Couldn't match type ‘Propellor.Types.MetaTypes.CheckCombinable
(Propellor.Types.MetaTypes.Concat
(Propellor.Types.MetaTypes.NonTargets y0)
(Data.Type.Bool.If
(Propellor.Types.MetaTypes.Elem
('Propellor.Types.MetaTypes.Targeting 'OSDebian)
(Propellor.Types.MetaTypes.Targets y0))
('Propellor.Types.MetaTypes.Targeting 'OSDebian
: Data.Type.Bool.If
(Propellor.Types.MetaTypes.Elem
('Propellor.Types.MetaTypes.Targeting 'OSBuntish)
-- many, many lines elided
• In the first argument of ‘(&)’, namely
‘props & osDebian Unstable’
The type-errors library was a big help. It's able to detect when the type checker gets "stuck" reducing a type function, and is going to dump it all out to the user. And you can replace that with a custom type error, like this one:
• Cannot combine properties:
Property <unknown>
Property HasInfo + Debian + Buntish + ArchLinux + FreeBSD
(Property <unknown> is often caused by applying a Property constructor to the wrong number of arguments.)
• In the first argument of ‘(&)’, namely
‘props & osDebian Unstable’
Detecting when the type checker is "stuck" also let me add some custom type errors to handle cases where type inference has failed:
• ensureProperty outer Property type is not able to be inferred here.
Consider adding a type annotation.
• When checking the inferred type
writeConfig :: forall (outer :: [Propellor.Types.MetaTypes.MetaType]) t.
• Unable to infer desired Property type in this use of tightenTargets.
Consider adding a type annotation.
Unfortunately, the use of TypeError caused one problem. When too many arguments are passed to a property constructor that's being combined with other properties, ghc used to give its usual error message about too many arguments, but now it gives the custom "Cannot combine properties" type error, which is not as useful.
Seems likely that's a ghc bug but I need a better test case to make progress on that front. Anyway, I decided I can live with this problem for now, to get all the other nice custom type errors.
The only other known problem with propellor's type errors is that, when there is a long list of properties being combined together, a single problem can result in a cascade of many errors. Sometimes that also causes ghc to use a lot of memory. While custom error messages don't help with this, at least the error cascade is nicer and individual messages are not as long.
Propellor 5.9.0 has all the custom type error messages discussed here. If you see a hard to understand error message when using it, get in touch and let's see if we can make it better.
This was sponsored by Jake Vosloo and Trenton Cronholm on Patreon.
Took a while to find the necessary serial cables and SD cards to test propellor's ARM disk image generation capabilies.
Ended up adding support for the SheevaPlug because it was the first board I found the hardware to test. And after fixing a couple oversights, it worked on the second boot!
Then after a trip to buy a microSD card, Olimex Lime worked on the first boot! So did CubieTruck and Banana Pi. I went ahead and added a dozen other sunxi boards that Debian supports, which will probably all work.
(Unfortunately I accidentially corrupted the disk of my home server (router/solar power monitor/git-annex build box) while testing the CubieTruck. Luckily, that server was the first ARM board I want to rebuild cleanly with propellor, and its configuration was almost entirely in propellor already, so rebuilding it now.)
Today's work was sponsored by Trenton Cronholm on Patreon.
Working today on adding support for ARM boards to propellor.
I started by adding support for generating non-native chroots.
qemu-debootstrap makes that fairly simple. Propellor is able to run
inside a non-native chroot too, to ensure properties in there;
the way it injects itself into a chroot wins again as that just worked.
Then, added support for flash-kernel, and for u-boot installation.
Installing u-boot to the boot sector of SD cards used by common ARM boards
does not seem to be automated anywhere in Debian, just README.Debian files
document dd commands. It may be that's not needed for a lot of boards
(my CubieTruck boots without it), but I implemented it anyway.
And, Propellor.Property.Machine is a new module with properties for different ARM boards, to get the right kernel/flash-kernel/u-boot/etc configuration easily.
This all works, and propellor can update a bootable disk image for an ARM system in 30 seconds. I have not checked yet if it's really bootable.
Tomorrow, I'm going to dust off my ARM boards and try to get at least 3 boards tested, and if that goes well, will probably add untested properties for all the rest of the sunxi boards.
Today's work was sponsored by Jake Vosloo on Patreon.
Built a new haskell library, http://hackage.haskell.org/package/scuttlebutt-types
I've been using Secure Scuttlebutt for 6 months or so, and think it's a rather good peer-to-peer social network. But it's very Javascript centric, and I want to be able to play with its data from Haskell.
The scuttlebutt-types library is based on some earlier work by Peter Hajdu. I expanded it to be have all the core Scuttlebutt data types, and got it parsing most of the corpus of Scuttlebutt messages. That took most of yesterday and all of today. The next thing to tackle would be generating JSON for messages formatted so the network accepts it.
I don't know what scuttlebutt-types will be used for. Maybe looking up stats, or building bots, or perhaps even a Scuttlebutt client? We'll see..
Today's work was sponsored by Trenton Cronholm on Patreon.
One of my initial goals for secret-project was for it to not need to implement a progress bar.

So, of course, today I found myself implementing a progress bar to finish up secret-project. As well as some other UI polishing, and fixing a couple of bugs in propellor that impacted it.
Ok, I'm entirely done with secret-project now, except for an unveiling later this month. Looking back over the devblog, it took only around 14 days total to build it all. Feels longer, but not bad!
After a rather interesting morning, the secret-project is doing exactly what I set out to accomplish! It's alllive!
(I found a way to segfault the ghc runtime first. And then I also managed to crash firefox, and finally managed to crash and hard-hang rsync.)
All that remains to be done now is to clean up the user interface. I made propellor's output be displayed in the web browser, but currently it contains ansi escape sequences which don't look good.
This would probably be a bad time to implement a in-browser terminal emulator in haskell, and perhaps a good time to give propellor customizable output backends. I have 3 days left to completely finish this project.
One last detour: Had to do more work than I really want to at this stage, to make the secret-project pick a good disk to use. Hardcoding a disk device was not working reliably enough even for a demo. Ended up with some fairly sophisticated heuristics to pick the right disk, taking disk size and media into account.
Then finally got on with grub installation to the target disk. Installing grub to a disk from a chroot is a fiddley process hard to get right. But, I remembered writing similar code before; propellor installs grub to a disk image from a chroot. So I generalized that special-purpose code to something the secret-project can also use.
It was a very rainy day, and rain fade on the satellite internet prevented me from testing it quickly. There were some dumb bugs. But at 11:30 pm, it Just Worked! Well, at least the target booted. /etc/fstab is not 100% right.
Late Friday evening, I realized that the secret-project's user interface should be a specialized propellor config file editor. Eureka! With that in mind, I reworked how the UserInput value is passed from the UI to propellor; now there's a UserInput.hs module that starts out with an unconfigured value, and the UI rewrites that file. This has a lot of benefits, including being able to test it without going through the UI, and letting the UI be decoupled into a separate program.
Also, sped up propellor's disk image building a lot. It already had some efficiency hacks, to reuse disk image files and rsync files to the disk image, but it was still repartitioning the disk image every time, and the whole raw disk image was being copied to create the vmdk file for VirtualBox. Now it only repartitions when something has changed, and the vmdk file references the disk image, which sped up the secret-project's 5 gigabyte image build time from around 30 minutes to 30 seconds.
With that procrastinationWgroundwork complete, I was finally at the point of testing the secret-project running on the disk image. There were a few minor problems, but within an hour it was successfully partitioning, mounting, and populating the target disk.
Still have to deal with boot loader installation and progress display, but the end of the secret-project is in sight.
Today's work was sponsored by Trenton Cronholm on Patreon.
The secret-project can probably partition disks now. I have not tried it yet.
I generalized propellor's PartSpec DSL, which had been used for only auto-fitting disk images to chroot sizes, to also support things like partitions that use some percentage of the disk.
A sample partition table using that, that gives / and /srv each 20% of
the disk, has a couple of fixed size partitions, and uses the rest for /home:
[ partition EXT2 `mountedAt` "/boot"
`setFlag` BootFlag
`setSize` MegaBytes 512
, partition EXT4 `mountedAt` "/"
`useDiskSpace` (Percent 20)
, partition EXT4 `mountedAt` "/srv"
`useDiskSpace` (Percent 20)
, partition EXT4 `mountedAt` "/home"
`useDiskSpace` RemainingSpace
, swapPartition (MegaBytes 1024)
]
It would probably be good to extend that with a combinator that sets
a minimum allows size, so eg / can be made no smaller than 4 GB.
The implementation should make it simple enough to add such combinators.
I thought about reusing the disk image auto-fitting code, so the
target's / would start at the size of the installer's /.
May yet do that; it would make some sense when the target and
installer are fairly similar systems.
After building the neato Host versioning described in Functional Reactive Propellor this weekend, I was able to clean up secret-project's config file significantly It's feeling close to the final version now.
At this point, the disk image it builds is almost capable of installing the target system, and will try to do so when the user tells it to. But, choosing and partitioning of the target system disk is not implemented yet, so it installs to a chroot which will fail due to lack of disk space there. So, I have not actually tested it yet.
Integrating propellor and secret-project stalled out last week. The problem was that secret-project can only be built with stack right now (until my patch to threepenny-gui to fix drag and drop handling gets accepted), but propellor did not support building itself with stack.
I didn't want to get sucked into yak shaving on that, and tried to find another approach, but finally gave in, and taught propellor how to build itself with stack. There was an open todo about that, with a hacky implementation by Arnaud Bailly, which I cleaned up.
Then the yak shaving continued as I revisited a tricky intermittent propellor bug. Think I've finally squashed that.
Finally, got back to where I left off last week, and at last here's a result! This is a disk image that was built entirely from a propellor config file, that contains a working propellor installation, and that starts up secret-project on boot.
Now to make this secret-project actually do something more than looking pretty..
Today's work was sponsored by Trenton Cronholm on Patreon.
This was a one step forward, one step back kind of day, as I moved the working stuff from yesterday out of my personal propellor config file and into the secret-project repository, and stumbled over some issues while doing so.
But, I had a crucial idea last night. When propellor is used to build an installer image, the installer does not need to bootstrap the target system from scratch. It can just copy the installer to the target system, and then run propellor there, with a configuration that reverts any properties that the installer had but the installed system should not. This will be a lot faster and avoid duplicate downloads.
That's similar to how d-i's live-installer works, but simpler, since with propellor there's a short list of all the properties that the installer has, and propellor knows if a property can be reverted or not.
Today's work was sponsored by Riku Voipio.
Doing a bunch of work on propellor this week. Some bug fixes and improvements to disk image building. Also some properties involving the XFCE desktop environment.
Putting it all together, I have 28 lines of propellor config file that generates a disk image that boots to a XFCE desktop and also has propellor installed. I wonder where it will go from here? ;-)
darkstar :: Host
darkstar = host "darkstar.kitenet.net" $ props
...
& imageBuilt "/srv/propellor-disk.img"
(Chroot.hostChroot demo (Chroot.Debootstrapped mempty))
MSDOS (grubBooted PC)
[ partition EXT2 `mountedAt` "/boot"
`setFlag` BootFlag
, partition EXT4 `mountedAt` "/"
`mountOpt` errorReadonly
`addFreeSpace` MegaBytes 256
, swapPartition (MegaBytes 256)
]
demo :: Host
demo = host "demo" $ props
& osDebian Unstable X86_64
& Apt.installed ["linux-image-amd64"]
& bootstrappedFrom GitRepoOutsideChroot
& User.accountFor user
& root `User.hasInsecurePassword` "debian"
& user `User.hasInsecurePassword` "debian"
& XFCE.installedMin
& XFCE.networkManager
& XFCE.defaultPanelFor user File.OverwriteExisting
& LightDM.autoLogin user
& Apt.installed ["firefox"]
where
user = User "user"
root = User "root"
Indcidentially, I have power and bandwidth to work on this kind of propellor stuff from home all day, for the first time! Up until now, all propellor features involving disk images were either tested remotely, or developed while I was away from home. It's a cloudy, rainy day; the solar upgrade and satellite internet paid off.
Today's work was sponsored by Riku Voipio.
And now for something completely different..
What is this strange thing? It's a prototype, thrown together with open clip art in a long weekend. It's an exploration how far an interface can diverge from the traditional and still work. And it's a mini-game.
Watch the video, and at the end, try to answer these questions:
- What will you do then?
- What happens next?
Spoilers below...

What I hope you might have answered to those questions, after watching the video, is something like this:
- What will you do then?
I'll move the egg into the brain-tree. - What happens next?
It will throw away the junk I had installed and replace it with what's in the egg.
The interface I'm diverging from is this kind of thing:

My key design points are these:
Avoid words entirely
One of my takeaways from the Debian installer project is that it's important to make the interface support non-English users, but maintaining translations massively slows down development. I want an interface that can be quickly iterated on or thrown away.
Massively simplify
In the Debian installer, we never managed to get rid of as many questions as we wanted to. I'm starting from the other end, and only putting in the absolute most essential questions.
- Do you want to delete everything that is on this computer?
- What's the hostname?
- What account to make?
- What password to use?
I hope to stop at the first that I've implemented so far. It should be possible to make the hostname easy to change after installation, and for an end user installation, the username doesh't matter much, and the password generally adds little or no security (and desktop environments should make it easy to add a password later).
Don't target all the users
Trying to target all users constrained the Debian installer in weird ways while complicating it massively.
This if not for installing a server or an embedded system. This interface is targeting end users who want a working desktop system with minimum fuss, and are capable of seeing and dragging. There can be other interfaces for other users.
Make it fun
Fun to use, and also fun to develop.
I'm using threepenny-gui to build the insterface. This lets Haskell code be written that directly manipulates the web browser's DOM. I'm having a lot of fun with that and can already think of other projects I can use threepenny-gui with!
Previously: propellor is d-i 2.0
Releasing debug-me 1.20170520 today with a major improvement.
Now it will look for the gpg key of the developer in keyring
files in /usr/share/debug-me/keyring/, and tell the user which project(s)
the developer is known to be a member of. So, for example, Debian
developers who connect to debug-me sessions of Debian users will be
identified as a Debian developer. And when I connect to a debug-me user's
session, debug-me will tell them that I'm the developer of debug-me.
This should help the user decide when to trust a developer to connect to their debug-me session. If they develop software that you're using, you already necessarily trust them and letting them debug your machine is not a stretch, as long as it's securely logged.
Thanks to Sean Whitton for the idea of checking the Debian keyring, which I've generalized to this.
Also, debug-me is now just an apt-get away for Debian unstable users, and I think it may end up in the next Debian release.
debug-me is released! https://debug-me.branchable.com/
I made one last protocol compatibility breaking change before the release. Realized that while the websocket framing protocol has a version number, the higher-level protocol does not, which would made extending it very hard later. So, added in a protocol version number.
The release includes a tarball that should let debug-me run on most linux systems. I adapted the code from git-annex for completely linux distribution-independent packaging. That added 300 lines of code to debug-me's source tree, which is suboptimal. But all the options in the Linux app packaging space are suboptimal. Flatpak and snappy would both be ok -- if the other one didn't exist and they were were installed everywhere. Appimage needs the program to be built against an older version of libraries.
Recorded a 7 minute screencast demoing debug-me, and another 3 minute screencast talking about its log files. That took around 5 hours of work actually, between finding a screencast program that works well (I used kazam), writing the "script", and setting the scenes for the user and developer desktops shown in the screencast.
While recording, I found a bug in debug-me. The gpg key was not available when it tried to verify it. I thought that I had seen gpg --verify --keyserver download a key from a keyserver and use it to verify but seems I was mistaken. So I changed the debug-me protocol to include the gpg public key, so it does not need to rely on accessing a keyserver.
Also deployed a debug-me server, http://debug-me.joeyh.name:8081/. It's not ideal for me to be running the debug-me server, because when me and a user are using that server with debug-me, I could use my control of the server to prevent the debug-me log being emailed to them, and also delete their local copy of the log.
I have a plan to https://debug-me.branchable.com/todo/send_to_multiple_servers/ that will avoid that problem but it needs a debug-me server run by someone else. Perhaps that will happen once I release debug-me; for now the single debug-me server will have to do.
Finally, made debug-me --verify log check all the signatures and hashes
in the log file, and display the gpg keys of the participants in the
debug-me session.
Today's work was sponsored by Jake Vosloo on Patreon.
(Also, Sean Whitton has stepped up to get debug-me into Debian!)
Added an additional hash chain of entered values to the debug-me data types. This fixes the known problem with debug-me's proof chains, that the order of two entered values could be ambiguous.
And also, it makes for nicer graphs! In this one, I typed "qwertyuiop" with high network lag, and you can see that the "r" didn't echo back until "t" "y" "u" had been entered. Then the two diverged states merged back together when "i" was entered chaining back to the last seen "r" and last entered "u".
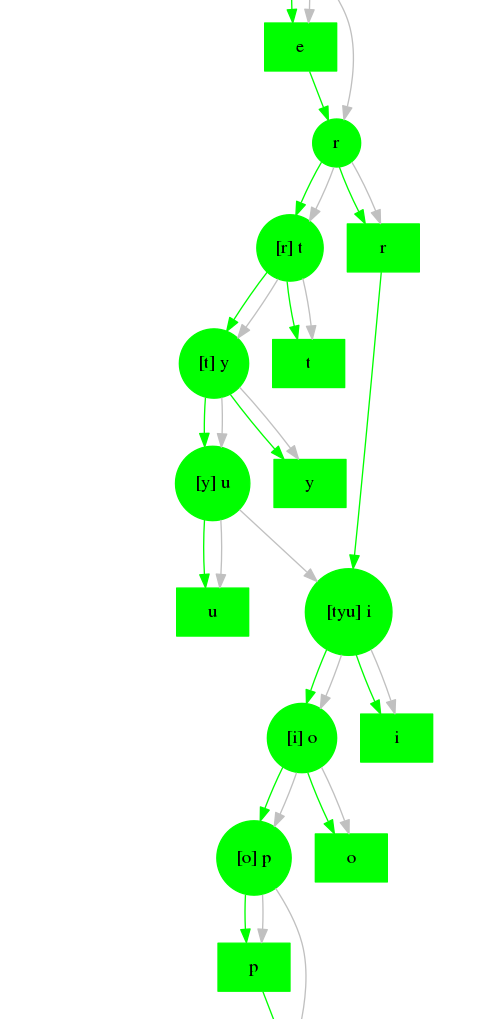
(Compare with the graph of the same kind of activity back in debug me first stage complete.)
Having debug-me generate these graphs has turned out to be a very good idea. Makes analyzing problems much easier.
Also made /quit in the control window quit the debug-me session.
I want to also let the user pause and resume entry in the session, but
it seems that could lead to more ambiguity problems in the proof chain,
so I'll have to think that over carefully.
debug-me seems ready for release now, except it needs some servers, and some packages, and a screencast showing how it works.
Today's work was sponsored by Trenton Cronholm on Patreon.
Fixed a tricky race condition that I think was responsible for some recent instability seen in debug-me when connecting to a session. It's a bit hard to tell because it caused at least 3 different types of crashes, and it was a race condition.
Made debug-me prompt for the user's email address when it starts up, and then the server will email the session log to the user at the end. There are two reasons to do this. First, it guards against the developer connecting to the session, doing something bad, and deleting the user's local log file to cover their tracks. Second, it means the server doesn't have to retain old log files, which could be abused to store other data on servers.
Also put together a basic web site, https://debug-me.branchable.com/.
Working on making debug-me verify the developer's gpg key. Here's what the user sees when I connect to them:
** debug-me session control and chat window
Someone wants to connect to this debug-me session.
Checking their Gnupg signature ...
gpg: Signature made Sat Apr 29 14:31:37 2017 JEST
gpg: using RSA key 28A500C35207EAB72F6C0F25DB12DB0FF05F8F38
gpg: Good signature from "Joey Hess <joeyh@joeyh.name>" [unknown]
gpg: aka "Joey Hess <id@joeyh.name>" [unknown]
gpg: aka "Joey Hess <joey@kitenet.net>" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Checking the Gnupg web of trust ...
Joey Hess's identity has been verified by as many as 111 people, including:
Martin Michlmayr, Kurt Gramlich, Luca Capello, Christian Perrier, Axel Beckert,
Stefano Zacchiroli, Gerfried Fuchs, Eduard Bloch, Anibal Monsalve Salazar
Joey Hess is probably a real person.
Let them connect to the debug-me session and run commands? [y/n]
And here's what the user sees when a fake person connects:
** debug-me session control and chat window
Someone wants to connect to this debug-me session.
Checking their Gnupg signature ...
gpg: Signature made Sat Apr 29 14:47:29 2017 JEST
gpg: using RSA key
gpg: Good signature from "John Doe" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: B2CF F6EF 2F01 96B1 CD2C 5A03 16A1 2F05 4447 4791
Checking the Gnupg web of trust ...
Their identity cannot be verified!
Let them connect to the debug-me session and run commands? [y/n]
The debug-me user is likely not be connected to the gpg web of trust, so debug-me will download the developer's key from a keyserver, and uses the https://pgp.cs.uu.nl/ service to check if the developer's key is in the strong set of the web of trust. It prints out the best-connected people who have signed the developer's key, since the user might recognise some of those names.
While relying on a server to determine if the developer is in the strong set is not ideal, it would be no better to have debug-me depend on wotsap, because wotsap still has to download the WoT database. (Also, the version of wotsap in debian is outdated and insecure) The decentralized way is for the user do some key signing, get into the WoT, and then gpg can tell them if the key is trusted itself.
debug-me is now nearly feature-complete!
It has some bugs, and a known problem with the evidence chain that needs to be fixed. And, I want to make debug-me servers email logs back to users, which will change the websockets protocol, so ought to be done before making any release.
I've been trying to write a good description of debug-me, and here's what I've got so far:
Short description: "secure remote debugging"
Long description:
Debugging a problem over email is slow, tedious, and hard. The developer needs to see the your problem to understand it. Debug-me aims to make debugging fast, fun, and easy, by letting the developer access your computer remotely, so they can immediately see and interact with the problem. Making your problem their problem gets it fixed fast.
A debug-me session is logged and signed with the developer's Gnupg key, producing a chain of evidence of what they saw and what they did. So the developer's good reputation is leveraged to make debug-me secure.
When you start debug-me without any options, it will connect to a debug-me server, and print out an url that you can give to the developer to get them connected to you. Then debug-me will show you their Gnupg key and who has signed it. If the developer has a good reputation, you can proceed to let them type into your console in a debug-me session. Once the session is done, the debug-me server will email you the signed evidence of what the developer did in the session.
If the developer did do something bad, you'd have proof that they cannot be trusted, which you can share with the world. Knowing that is the case will keep most developers honest.
I think that's pretty good, and would like to know your thoughts, reader, as a prospective debug-me user.
Most of today was spent making debug-me --control communicate over a socket
with the main debug-me process. That is run in a separate window,
which is the debug-me session control and chat window. Things typed there
can be seen by the other people involved in a debug-me session. And, the gnupg
key prompting stuff will be done in that window eventually.
Screenshot of the first time that worked. The "user" is on the left and the "developer" is on the right.
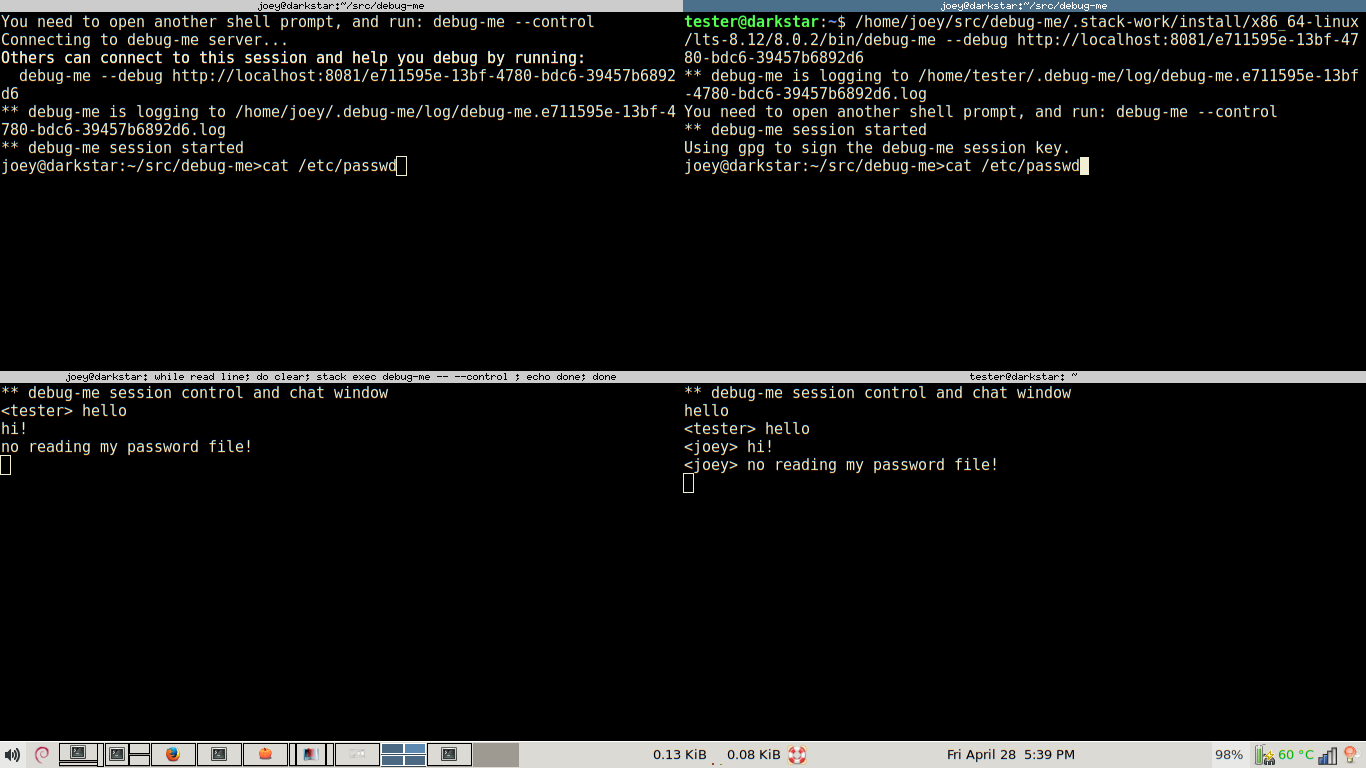
Went ahead and made debug-me use protocol buffers for its wire protocol. There's a nice haskell library for this that doesn't depend on anything else, and can generate them directly from data types, but I had to write a shim between the protobuf style data types and debug-me's internal data types. Took 250 lines of quite tedious code.
Then I finally implemented the trick I thought of to leave out the previous hash from debug-me messages on the wire, while still including cryptograhically secure proof of what the previous hash was. That reduced the overhead of a debug-me message from 168 bytes to 74 bytes!
I doubt debug-me's wire format will see any more major changes.
How does debug-me compare with ssh? I tried some experiments, and typing a character in ssh sends 180 bytes over the wire, while doing the same in debug-me sends 326 bytes. The extra overhead must be due to using websockets, I guess. At least debug-me is in the same ballpark as ssh.
Today's work was sponsored by Riku Voipio.
Working on polishing up debug-me's features to not just work, but work well.
On Monday, I spent much longer than expected on the problem that when a debug-me session ended, clients attached to it did not shut down. The session shutdown turned out to have worked by accident in one case, but it was lacking a proper implementation, and juggling all the threads and channels and websockets to get everything to shut down cleanly was nontrivial.
Today, I fixed a bug that made debug-me --download fail while downloading a
session, because the server didn't relay messages from developers, and so
the proof chain was invalid. After making the server relay those messages,
and handling them, that was fixed -- and I got a great feature for free:
Multiple developers can connect to a debug-me session and all interact with
it at the same time!
Also, added timing information to debug-me messages. While time is relative
and so it can't be proved how long the time was between messages in the
debug-me proof chain, including that information lets debug-me --download
download a session and then debug-me --replay can replay the log file
with realistic pauses.
Started on gpg signing and signature verification, but that has a user interface problem. If the developer connects after the debug-me session has started, prompting the user on the same terminal that is displaying the session would not be good. This is where it'd be good to have a library for multi-terminal applications. Perhaps I should go build a prototype of that. Of perhaps I'll make debug-me wait for one developer to connect and prompt the user before starting the session.
Got debug-me fully working over the network today. It's allllive!
Hardest thing today was when a developer connects and the server needs to send them the backlog of the session before they start seeing current activity. Potentially full of races. My implementation avoids race conditions, but might cause other connected developers to see a stall in activity at that point. A stall-free version is certianly doable, but this is good enough for now.
There are quite a few bugs to fix. Including a security hole in the proof chain design, that I realized it had when thinking about what happens with multiple people are connected to a debug-me session who are all typing at once.
(There have actually been 3 security holes spotted over the past day; the one above, a lacking sanitization of session IDs, and a bug in the server that let a developer truncate logs.)
So I need to spend several mode days bugfixing, and also make it only allow connections signed by trusted gpg keys. Still, an initial release does not seem far off now.
Worked today on making debug-me run as a client/server, communicating using websockets.
I decided to use the "binary" library to get an efficient serialization of debug-me's messages to send over the websockets, rather than using JSON. A typically JSON message was 341 bytes, and this only uses 165 bytes, which is fairly close to the actual data size of ~129 bytes. I may later use protocol buffers to make it less of a haskell-specific wire format.
Currently, the client and server basically work; the client can negotiate a protocol version with the server and send messages to it, which the server logs.
Also, added two additional modes to debug-me. debug-me --download url will
download a debug-me log file. If that session is still running, it keeps
downloading until it's gotten the whole session. debug-me --watch url
connects to a debug-me session, and displays it in non-interactive mode.
These were really easy to implement, reusing existing code.
Added signatures to the debug-me protocol today. All messages are signed using a ed25519 session key, and the protocol negotiates these keys.
Here's a dump of a debug-me session, including session key exchange:
{"ControlMessage":{"control":{"SessionKey":[{"b64":"it8RIgswI8IZGjjQ+/INPjGYPAcGCwN9WmGZNlMFoX0="},null]},"controlSignature":{"Ed25519Signature":{"b64":"v80m5vQbgw87o88+oApg0syUk/vg88t14nIfXzahwAqEes/mqY4WWFIbMR46WcsEKP2fwfXQEN5/nc6UOagBCQ=="}}}}
{"ActivityMessage":{"prevActivity":null,"activitySignature":{"Ed25519Signature":{"b64":"HNPk/8QF7iVtsI+hHuO1+J9CFnIgsSrqr1ITQ2eQ4VM7rRPG7i07eKKpv/iUwPP4OdloSmoHLWZeMXZNvqnCBQ=="}},"activity":{"seenData":{"v":">>> debug-me session starting\r\n"}}}}
{"ActivityMessage":{"prevActivity":{"hashValue":{"v":"63d31b25ca262d7e9fc5169d137f61ecef20fb65c23c493b1910443d7a5514e4"},"hashMethod":"SHA256"},"activitySignature":{"Ed25519Signature":{"b64":"+E0N7j9MwWgFp+LwdzNyByA5W6UELh6JFxVCU7+ByuhcerVO/SC2ZJJJMq8xqEXSc9rMNKVaAT3Z6JmidF+XAw=="}},"activity":{"seenData":{"v":"$ "}}}}
{"ControlMessage":{"control":{"SessionKey":[{"b64":"dlaIEkybI5j3M/WU97RjcAAr0XsOQQ89ffZULVR82pw="},null]},"controlSignature":{"Ed25519Signature":{"b64":"hlyf7SZ5ZyDrELuTD3ZfPCWCBcFcfG9LP7Zuy+roXwlkFAv2VtpYrFAAcnWSvhloTmYIfqo5LWakITPI0ITtAQ=="}}}}
{"ControlMessage":{"control":{"SessionKeyAccepted":[{"b64":"dlaIEkybI5j3M/WU97RjcAAr0XsOQQ89ffZULVR82pw="},null]},"controlSignature":{"Ed25519Signature":{"b64":"kJ7AdhBgoiYfsXOM//4mcMcU5sL0oyqulKQHUPFo2aYYPJnu5rKUHlfNsfQbGDDrdsl9SocZaacUpm+FoiDCCg=="}}}}
{"ActivityMessage":{"prevActivity":{"hashValue":{"v":"2250d8b902683053b3faf5bdbe3cfa27517d4ede220e4a24c8887ef42ab506e0"},"hashMethod":"SHA256"},"activitySignature":{"Ed25519Signature":{"b64":"hlF7oFhFealsf8+9R0Wj+vzfb3rBJyQjUyy7V0+n3zRLl5EY88XKQzTuhYb/li+WoH/QNjugcRLEBjfSXCKJBQ=="}},"activity":{"echoData":{"v":""},"enteredData":{"v":"l"}}}}
Ed25519 signatures add 64 bytes overhead to each message, on top of the 64 bytes for the hash pointer to the previous message. But, last night I thought of a cunning plan to remove that hash pointer from the wire protocol, while still generating a provable hash chain. Just leave it out of the serialized message, but include it in the data that's signed. debug-me will then just need to try the hashes of recent messages until it finds one for which the signature verifies, and then it will know what the hash pointer is supposed to point to, without it ever having been sent over the wire! Will implement this trick eventually.
Next though, I need to make debug-me communicate over the network.
Solved that bug I was stuck on yesterday. I had been looking in the code for the developer side for a bug, but that side was fine; the bug was excessive backlog trimming on the user side.
Now I'm fairly happy with how debug-me's activity chains look,
and the first stage of developing debug-me is complete. It still doesn't do
anything more than the script command, but all the groundwork for the
actual networked debug-me is done now. I only have to add signing,
verification of gpg key trust, and http client-server to finish debug-me.
(Also, I made debug-me --replay debug-me.log replay the log with
realistic delays, like scriptreplay or ttyplay. Only took a page
of code to add that feature.)
I'm only "fairly happy" with the activity chains because there is a weird edge case.. At high latency, when typing "qwertyuiop", this happens:
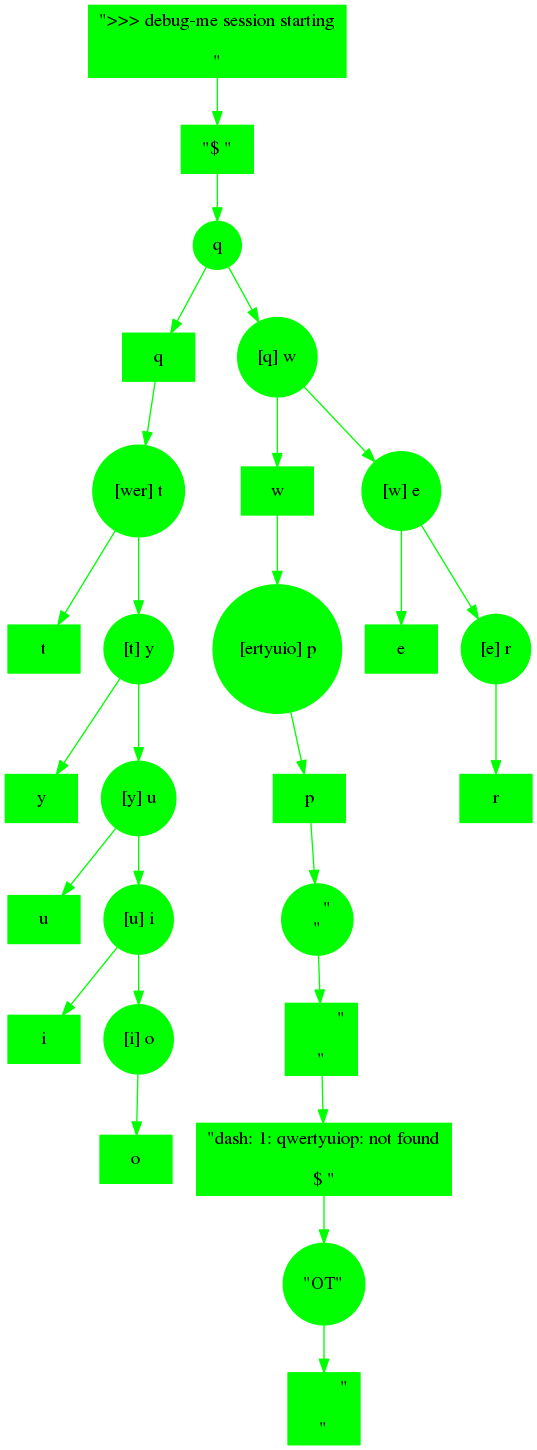
That looks weird, and is somewhat hard to follow in graph form, but it's "correct" as far as debug-me's rules for activity chains go. Due to the lag, the chain forks:
- It sends "wer" before the "q" echos back
- It replies to the "q" echo with tyuio" before the "w" echos back.
- It replies to the "w" echo with "p"
- Finally, all the delayed echos come in, and it sends a carriage return, resulting in the command being run.
I'd be happier if the forked chain explicitly merged back together, but to do that and add any provable information, the developer would have to wait for all the echos to arrive before sending the carriage return, or something like that, which would make type-ahead worse. So I think I'll leave it like this. Most of the time, latency is not so high, and so this kind of forking doesn't happen much or is much simpler to understand when it does happen.
Working on getting the debug-me proof chain to be the right shape, and be checked at all points for valididity. This graph of a session shows today'ss progress, but also a bug.
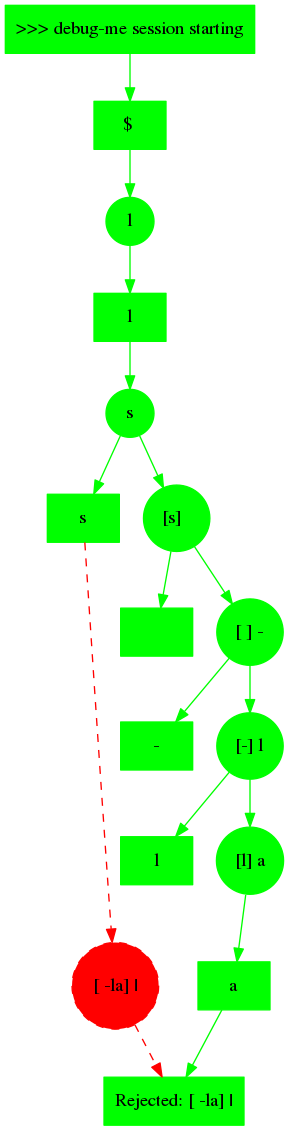
At the top, everything is synchronous while "ls" is entered and echoed back. Then, things go asynchronous when " -la" is entered, and the expected echos (in brackets) match up with what really gets echoed, so that input is also accepted.
Finally, the bit in red where "|" is entered is a bug on the developer side, and it gets (correctly) rejected on the user side due to having forked the proof chain. Currently stuck on this bug.
The code for this, especially on the developer side, is rather hairy, I wonder if I am missing a way to simplify it.
Two days only partially spent on debug-me..
Yesterday a few small improvements, but mostly I discovered the posix-pty library, and converted debug-me to use it rather than wrangling ptys itself. Which was nice because it let me fix resizing. However, the library had a bug with how it initializes the terminal, and investigating and working around that bug used up too much time. Oh well, probably still worth it.
Today, made debug-me serialize to and from JSON.
{"signature":{"v":""},"prevActivity":null,"activity":{"seenData":{"v":">>> debug-me session starting\r\n"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"fb4401a717f86958747d34f98c079eaa811d8af7d22e977d733f1b9e091073a6"},"hashMethod":"SHA256"},"activity":{"seenData":{"v":"$ "}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"cfc629125d93f55d2a376ecb9e119c89fe2cc47a63e6bc79588d6e7145cb50d2"},"hashMethod":"SHA256"},"activity":{"echoData":{"v":""},"enteredData":{"v":"l"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"cfc629125d93f55d2a376ecb9e119c89fe2cc47a63e6bc79588d6e7145cb50d2"},"hashMethod":"SHA256"},"activity":{"seenData":{"v":"l"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"3a0530c7739418e22f20696bb3798f8c3b2caf7763080f78bfeecc618fc5862e"},"hashMethod":"SHA256"},"activity":{"echoData":{"v":""},"enteredData":{"v":"s"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"3a0530c7739418e22f20696bb3798f8c3b2caf7763080f78bfeecc618fc5862e"},"hashMethod":"SHA256"},"activity":{"seenData":{"v":"s"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"91ac86c7dc2445c18e9a0cfa265585b55e01807e377d5f083c90ef307124d8ab"},"hashMethod":"SHA256"},"activity":{"echoData":{"v":""},"enteredData":{"v":"\r"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"91ac86c7dc2445c18e9a0cfa265585b55e01807e377d5f083c90ef307124d8ab"},"hashMethod":"SHA256"},"activity":{"seenData":{"v":"\r\n"}}}
{"signature":{"v":""},"prevActivity":{"hashValue":{"v":"cc97177983767a5ab490d63593011161e2bd4ac2fe00195692f965810e6cf3bf"},"hashMethod":"SHA256"},"activity":{"seenData":{"v":"AGPL\t Pty.hs Types.hs\t debug-me.cabal dist\r\nCmdLine.hs Setup.hs Val.hs\t debug-me.hs\t stack.yaml\r\n"}}}
That's a pretty verbose way of saying: I typed "ls" and saw the list of files. But it compresses well. Each packet for a single keystroke will take only 37 bytes to transmit as part of a compressed stream of JSON, and 32 of those bytes are needed for the SHA256 hash. So, this is probably good enough to use as debug-me's wire format.
(Some more bytes will be needed once the signature field is not empty..)
It's also a good logging format, and can be easily analized to eg, prove when a person used debug-me to do something bad.
Wrote a quick visualizor for debug-me logs using graphviz. This will be super useful for debug-me development if nothing else.
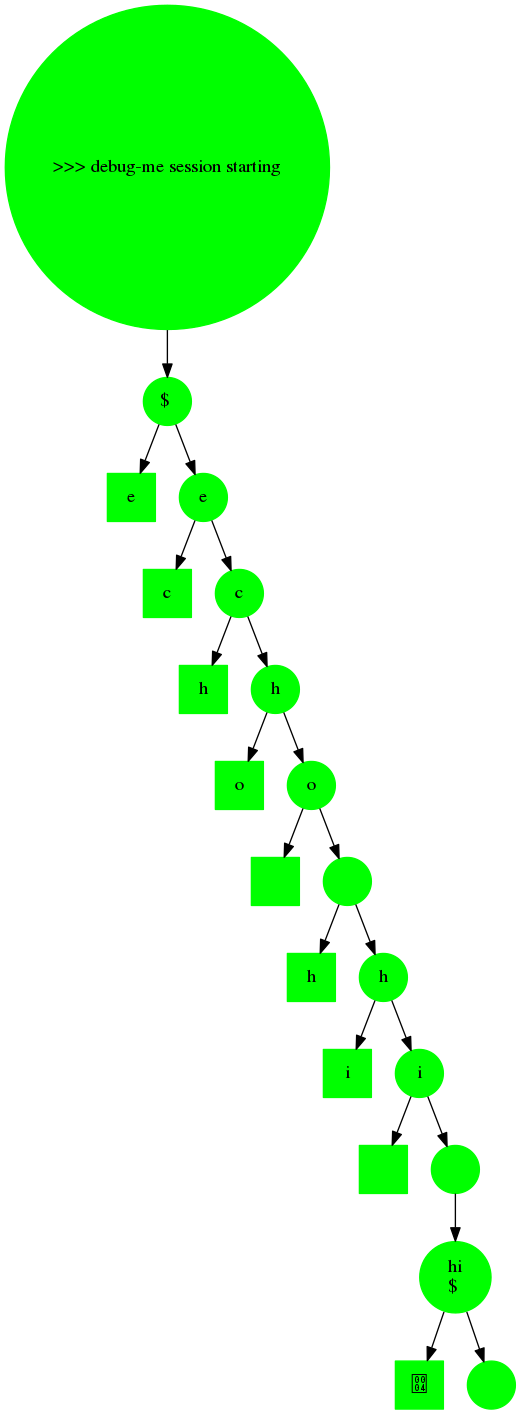
Proceeding as planned, I wrote 170 lines of code to make debug-me have separate threads for the user and developer sides, which send one-another updates to the activity chain, and check them for validity. This was fun to implement! And it's lacking only signing to be a full implementation of the debug-me proof chain.
Then I added a network latency simulation to it and tried different latencies up to the latency I measure on my satellite internet link (800 ms or so)
That helped me find two bugs, where it was not handling echo simulation correctly. Something is still not handled quite right, because when I put a network latency delay before sending output from the user side to the developer side, it causes some developer input to get rejected. So I'm for now only inserting latency when the developer is sending input to the user side. Good enough for proof-of-concept.
Result is that, even with a high latency, it feels "natural" to type commands into debug-me. The echo emulation works, so it accepts typeahead.
Using backspace to delete several letters in a row feels "wrong"; the synchronousness requirements prevent that working when latency is high. Same problem for moving around with the arrow keys. Down around 200 ms latency, these problems are not apparent, unless you mash down the backspace or arrow key.
How about using an editor? It seemed reasonably non-annoying at 200 ms latency, although here I do tend to mash down arrow keys and then it moves too fast for debug-me to keep up, and so the cursor movement stalls.
At higher latencies, using an editor was pretty annoying. Where I might normally press the down arrow key N distinct times to get to the line I wanted, that doesn't work in debug-me at 800 ms latency. Of course, over such a slow connection, using an editor is the last thing you want to do anyway, and vi key combos like 9j start to become necessary (and work in debug-me).
Based on these experiements, the synchronousness requirements are not as utterly annoying as I'd feared, especially at typical latencies.
And, it seems worth making debug-me detect when several keys are pressed close together, and send a single packet over the network combining those. That should make it behave better when mashing down a key.
Today's work was sponsored by Jake Vosloo on Patreon
Started some exploratory programming on the debug-me idea.
First, wrote down some data types for debug-me's proof of developer activity.
Then, some terminal wrangling, to get debug-me to allocate a
pseudo-terminal, run an interactive shell in it, and pass stdin
and stdout back and forth to the terminal it was started in.
At this point, debug-me is very similar to script, except
it doesn't log the data it intercepts to a typescript file.
Terminals are complicated, so this took a while, and it's still not perfect, but good enough for now. Needs to have resize handling added, and for some reason when the program exits, the terminal is left in a raw state, despite the program apparently resetting its attributes.
Next goal is to check how annoying debug-me's insistence on a synchronous activity proof chain will be when using debug-me across a network link with some latency. If that's too annoying, the design will need to be changed, or perhaps won't work.
To do that, I plan to make debug-me simulate a network between the user and developer's processes, using threads inside a single process for now. The user thread will builds up an activity chain, and only accepts inputs from the developer thread when they meet the synchronicity requirements. Ran out of time to finish that today, so next time.
debug-me's git repository is available from https://git.joeyh.name/index.cgi/debug-me.git/
Today's work was sponsored by andrea rota.
Worked for a while today on http://propellor.branchable.com/todo/property_to_install_propellor/, with the goal of making propellor build a disk image that itself contains propellor.
The hard part of that turned out to be that inside the chroot it's building, /usr/local/propellor is bind mounted to the one outside the chroot. But this new property needs to populate that directory in the chroot. Simply unmounting the bind mount would break later properties, so some way to temporarily expose the underlying directory was called for.
At first, I thought unshare -m could be used to do this, but for some
reason that does not work in a chroot. Pity. Ended up going with a
complicated dance, where the bind mount is bind mounted to a temp dir,
then unmounted to expose the underlying directory, and once it's set up,
the temp dir is re-bind-mounted back over it. Ugh.
I was able to reuse Propellor.Bootstrap to bootstrap propellor inside the chroot, which was nice.
Also nice that I'm able to work on this kind of thing at home despite it involving building chroots -- yay for satellite internet!
Today's work was sponsored by Riku Voipio.
Propellor was recently ported to FreeBSD, by Evan Cofsky. This new feature led me down a two week long rabbit hole to make it type safe. In particular, Propellor needed to be taught that some properties work on Debian, others on FreeBSD, and others on both.
The user shouldn't need to worry about making a mistake like this; the type checker should tell them they're asking for something that can't fly.
-- Is this a Debian or a FreeBSD host? I can't remember, let's use both package managers!
host "example.com" $ props
& aptUpgraded
& pkgUpgraded
As of propellor 3.0.0 (in git now; to be released soon), the type checker will catch such mistakes.
Also, it's really easy to combine two OS-specific properties into a property that supports both OS's:
upgraded = aptUpgraded `pickOS` pkgUpgraded
type level lists and functions
The magick making this work is type-level lists. A property has a metatypes list as part of its type. (So called because it's additional types describing the type, and I couldn't find a better name.) This list can contain one or more OS's targeted by the property:
aptUpgraded :: Property (MetaTypes '[ 'Targeting 'OSDebian, 'Targeting 'OSBuntish ])
pkgUpgraded :: Property (MetaTypes '[ 'Targeting 'OSFreeBSD ])
In Haskell type-level lists and other DataKinds are indicated by the
' if you have not seen that before. There are some convenience
aliases and type operators, which let the same types be expressed
more cleanly:
aptUpgraded :: Property (Debian + Buntish)
pkgUpgraded :: Property FreeBSD
Whenever two properties are combined, their metatypes are combined
using a type-level function. Combining aptUpgraded and pkgUpgraded
will yield a metatypes that targets no OS's, since they have none in
common. So will fail to type check.
My implementation of the metatypes lists is hundreds of lines of code, consisting entirely of types and type families. It includes a basic implementation of singletons, and is portable back to ghc 7.6 to support Debian stable. While it takes some contortions to support such an old version of ghc, it's pretty awesome that the ghc in Debian stable supports this stuff.
extending beyond targeted OS's
Before this change, Propellor's Property type had already been slightly
refined, tagging them with HasInfo or NoInfo, as described
in making propellor safer with GADTs and type families. I needed to
keep that HasInfo in the type of properties.
But, it seemed unnecessary verbose to have types like Property NoInfo Debian.
Especially if I want to add even more information to Property
types later. Property NoInfo Debian NoPortsOpen would be a real mouthful to
need to write for every property.
Luckily I now have this handy type-level list. So, I can shove more
types into it, so Property (HasInfo + Debian) is used where necessary,
and Property Debian can be used everywhere else.
Since I can add more types to the type-level list, without affecting other properties, I expect to be able to implement type-level port conflict detection next. Should be fairly easy to do without changing the API except for properties that use ports.
singletons
As shown here, pickOS makes a property that
decides which of two properties to use based on the host's OS.
aptUpgraded :: Property DebianLike
aptUpgraded = property "apt upgraded" (apt "upgrade" `requires` apt "update")
pkgUpgraded :: Property FreeBSD
pkgUpgraded = property "pkg upgraded" (pkg "upgrade")
upgraded :: Property UnixLike
upgraded = (aptUpgraded `pickOS` pkgUpgraded)
`describe` "OS upgraded"
Any number of OS's can be chained this way, to build a property that is super-portable out of simple little non-portable properties. This is a sweet combinator!
Singletons are types that are inhabited by a single value.
This lets the value be inferred from the type, which came in handy
in building the pickOS property combinator.
Its implementation needs to be able to look at each of the properties at
runtime, to compare the OS's they target with the actial OS of the host.
That's done by stashing a target list value inside a property. The target
list value is inferred from the type of the property, thanks to singletons,
and so does not need to be passed in to property. That saves
keyboard time and avoids mistakes.
is it worth it?
It's important to consider whether more complicated types are a net benefit. Of course, opinions vary widely on that question in general! But let's consider it in light of my main goals for Propellor:
- Help save the user from pushing a broken configuration to their machines at a time when they're down in the trenches dealing with some urgent problem at 3 am.
- Advance the state of the art in configuration management by taking advantage of the state of the art in strongly typed haskell.
This change definitely meets both criteria. But there is a tradeoff; it got a little bit harder to write new propellor properties. Not only do new properties need to have their type set to target appropriate systems, but the more polymorphic code is, the more likely the type checker can't figure out all the types without some help.
A simple example of this problem is as follows.
foo :: Property UnixLike
foo = p `requires` bar
where
p = property "foo" $ do
...
The type checker will complain that "The type variable ‘metatypes1’ is
ambiguous". Problem is that it can't infer the type of p because many
different types could be combined with the bar property and all would
yield a Property UnixLike. The solution is simply to add a type signature
like p :: Property UnixLike
Since this only affects creating new properties, and not combining existing properties (which have known types), it seems like a reasonable tradeoff.
things to improve later
There are a few warts that I'm willing to live with for now...
Currently, Property (HasInfo + Debian) is different than Property (Debian +
HasInfo), but they should really be considered to be the same type. That is, I
need type-level sets, not lists. While there's a type level sets library for
hackage, it still seems to
require a specific order of the set items when writing down a type signature.
Also, using ensureProperty, which runs one property inside the action
of another property, got complicated by the need to pass it a type witness.
foo = Property Debian
foo = property' $ \witness -> do
ensureProperty witness (aptInstall "foo")
That witness is used to type check that the inner property targets every OS that the outer property targets. I think it might be possible to store the witness in the monad, and have ensureProperty read it, but it might complicate the type of the monad too much, since it would have to be parameterized on the type of the witness.
Oh no, I mentioned monads. While type level lists and type functions and generally bending the type checker to my will is all well and good, I know most readers stop reading at "monad". So, I'll stop writing. ;)
thanks
Thanks to David Miani who answered my first tentative question with a big hunk of example code that got me on the right track.
Also to many other people who answered increasingly esoteric Haskell type system questions.
Also thanks to the Shuttleworth foundation, which funded this work by way of a Flash Grant.
I've integrated letsencrypt into propellor today.
I'm using the reference letsencrypt client. While I've seen complaints that
it has a lot of dependencies and is too complicated, it seemed to only need
to pull in a few packages, and use only a few megabytes of disk space, and
it has fewer options than ls does. So seems fine. (Although it would be
nice to have some alternatives packaged in Debian.)
I ended up implementing this:
letsEncrypt :: AgreeTOS -> Domain -> WebRoot -> Property NoInfo
This property just makes the certificate available, it does not configure the web server to use it. This avoids relying on the letsencrypt client's apache config munging, which is probably useful for many people, but not those of us using configuration management systems. And so avoids most of the complicated magic that the letsencrypt client has a reputation for.
Instead, any property that wants to use the certificate can just use leteencrypt to get it and set up the server when it makes a change to the certificate:
letsEncrypt (LetsEncrypt.AgreeTOS (Just "me@my.domain")) "example.com" "/var/www"
`onChange` setupthewebserver
(Took me a while to notice I could use onChange like that,
and so divorce the cert generation/renewal from the server setup.
onChange is awesome! This blog post has been updated accordingly.)
In practice, the http site has to be brought up first, and then letsencrypt run, and then the cert installed and the https site brought up using it. That dance is automated by this property:
Apache.httpsVirtualHost "example.com" "/var/www"
(LetsEncrypt.AgreeTOS (Just "me@my.domain"))
That's about as simple a configuration as I can imagine for such a website!
The two parts of letsencrypt that are complicated are not the fault of the client really. Those are renewal and rate limiting.
I'm currently rate limited for the next week because I asked letsencrypt for several certificates for a domain, as I was learning how to use it and integrating it into propellor. So I've not quite managed to fully test everything. That's annoying. I also worry that rate limiting could hit at an inopportune time once I'm relying on letsencrypt. It's especially problimatic that it only allows 5 certs for subdomains of a given domain per week. What if I use a lot of subdomains?
Renewal is complicated mostly because there's no good way to test it. You set up your cron job, or whatever, and wait three months, and hopefully it worked. Just as likely, you got something wrong, and your website breaks. Maybe letsencrypt could offer certificates that will only last an hour, or a day, for use when testing renewal.
Also, what if something goes wrong with renewal? Perhaps letsencrypt.org is not available when your certificate needs to be renewed.
What I've done in propellor to handle renewal is, it runs letsencrypt every time, with the --keep-until-expiring option. If this fails, propellor will report a failure. As long as propellor is run periodically by a cron job, this should result in multiple failure reports being sent (for 30 days I think) before a cert expires without getting renewed. But, I have not been able to test this.
Following up on Then and Now ...
In quiet moments at ICFP last August, I finished teaching Propellor to generate disk images. With an emphasis on doing a whole lot with very little new code and extreme amount of code reuse.
For example, let's make a disk image with nethack on it. First, we need to define a chroot. Disk image creation reuses propellor's chroot support, described back in propelling containers. Any propellor properties can be assigned to the chroot, so it's easy to describe the system we want.
nethackChroot :: FilePath -> Chroot
nethackChroot d = Chroot.debootstrapped (System (Debian Stable) "amd64") mempty d
& Apt.installed ["linux-image-amd64"]
& Apt.installed ["nethack-console"]
& accountFor gamer
& gamer `hasInsecurePassword` "hello"
& gamer `hasLoginShell` "/usr/games/nethack"
where gamer = User "gamer"
Now to make an image from that chroot, we just have to tell propellor where to put the image file, some partitioning information, and to make it boot using grub.
nethackImage :: RevertableProperty
nethackImage = imageBuilt "/srv/images/nethack.img" nethackChroot
MSDOS (grubBooted PC)
[ partition EXT2 `mountedAt` "/boot"
`setFlag` BootFlag
, partition EXT4 `mountedAt` "/"
`addFreeSpace` MegaBytes 100
, swapPartition (MegaBytes 256)
]
The disk image partitions default to being sized to fit exactly the files
from the chroot that go into each partition, so, the disk image is as small
as possible by default. There's a little DSL to configure the partitions.
To give control over the partition size, it has some functions, like
addFreeSpace and setSize. Other functions like setFlag and
extended can further adjust the partitions. I think that worked out
rather well; the partition specification is compact and avoids unecessary
hardcoded sizes, while providing plenty of control.
By the end of ICFP, I had Propellor building complete disk images, but no boot loader installed on them.
Fast forward to today. After stuggling with some strange grub behavior, I found a working method to install grub onto a disk image.
The whole disk image feature weighs in at:
203 lines to interface with parted
88 lines to format and mount partitions
90 lines for the partition table specification DSL and partition sizing
196 lines to generate disk images
75 lines to install grub on a disk image
652 lines of code total
Which is about half the size of vmdebootstrap 1/4th the size of partman-base (probably 1/100th the size of total partman), and 1/13th the size of live-build. All of which do similar things, in ways that seem to me to be much less flexible than Propellor.
One thing I'm considering doing is extending this so Propellor can use qemu-user-static to create disk images for eg, arm. Add some u-boot setup, and this could create bootable images for arm boards. A library of configs for various arm boards could then be included in Propellor. This would be a lot easier than running the Debian Installer on an arm board.
Oh! I only just now realized that if you have a propellor host configured,
like this example for my dialup gateway, leech --
leech = host "leech.kitenet.net"
& os (System (Debian (Stable "jessie")) "armel")
& Apt.installed ["linux-image-kirkwood", "ppp", "screen", "iftop"]
& privContent "/etc/ppp/peers/provider"
& privContent "/etc/ppp/pap-secrets"
& Ppp.onBoot
& hasPassword (User "root")
& Ssh.installed
-- The host's properties can be extracted from it, using eg
hostProperties leech and reused to create a disk image with
the same properties as the host!
So, when my dialup gateway gets struck by lightning again, I could use this to build a disk image for its replacement:
import qualified Propellor.Property.Hardware.SheevaPlug as SheevaPlug
laptop = host "darkstar.kitenet.net"
& SheevaPlug.diskImage "/srv/images/leech.img" (MegaBytes 2000)
(& propertyList "has all of leech's properties"
(hostProperties leech))
This also means you can start with a manually built system, write down the properties it has, and iteratively run Propellor against it until you think you have a full specification of it, and then use that to generate a new, clean disk image. Nice way to transition from sysadmin days of yore to a clean declaratively specified system.
With the disclamer that I don't really know much about orchestration, I have added support for something resembling it to Propellor.
Until now, when using propellor to manage a bunch of hosts, you
updated them one at a time by running propellor --spin $somehost,
or maybe you set up a central git repository, and a cron job to run
propellor on each host, pulling changes from git.
I like both of these ways to use propellor, but they only go so far...
Perhaps you have a lot of hosts, and would like to run propellor on them all concurrently.
master = host "master.example.com" & concurrently conducts alotofhostsPerhaps you want to run propellor on your dns server last, so when you add a new webserver host, it gets set up and working before the dns is updated to point to it.
master = host "master.example.com" & conducts webservers `before` conducts dnsserverPerhaps you have something more complex, with multiple subnets that propellor can run in concurrently, finishing up by updating that dnsserver.
master = host "master.example.com" & concurrently conducts [sub1, sub2] `before` conducts dnsserver sub1 = "master.subnet1.example.com" & concurrently conducts webservers & conducts loadbalancers sub2 = "master.subnet2.example.com" & conducts dockerserversPerhaps you need to first run some command that creates a VPS host, and then want to run propellor on that host to set it up.
vpscreate h = cmdProperty "vpscreate" [hostName h] `before` conducts h
All those scenarios are supported by propellor now!
Well, I
haven't actually implemented concurrently yet,
but the point is that the conducts property can be used with any
of propellor's property combinators, like before etc,
to express all kinds of scenarios.
The conducts property works in combination with an orchestrate function
to set up all the necessary stuff to let one host ssh into another and run
propellor there.
main = defaultMain (orchestrate hosts)
hosts =
[ master
, webservers
, ...
]
The orchestrate function does a bunch of stuff:
- Builds up a graph of what conducts what.
- Removes any cycles that might have snuck in by accident, before they cause foot shooting.
- Arranges for the ssh keys to be accepted as necessary.
Note that you you need to add ssh key properties to all relevant hosts so it knows what keys to trust. - Arranges for the private data of a host to be provided to the hosts that conduct it, so they can pass it along.
I've very pleased that I was able to add the Propellor.Property.Conductor module implementing this with only a tiny change to the rest of propellor. Almost everything needed to implement it was there in propellor's infrastructure already.
Also kind of cool that it only needed 13 lines of imperative code, the other several hundred lines of the implementation being all pure code.
I've been doing a little bit of dynamically typed programming in Haskell,
to improve Propellor's Info type. The result is kind of
interesting in a scary way.
Info started out as a big record type, containing all the different sorts
of metadata that Propellor needed to keep track of. Host IP addresses, DNS
entries, ssh public keys, docker image configuration parameters... This got
quite out of hand. Info needed to have its hands in everything,
even types that should have been private to their module.
To fix that, recent versions of Propellor let a single
Info contain many different types of values. Look at it one way and
it contains DNS entries; look at it another way and it contains ssh public
keys, etc.
As an émigré from lands where you can never know what type of value is in
a $foo until you look, this was a scary prospect at first, but I found
it's possible to have the benefits of dynamic types and the safety of
static types too.
The key to doing it is Data.Dynamic. Thanks to Joachim Breitner for
suggesting I could use it here. What I arrived at is this type (slightly
simplified):
newtype Info = Info [Dynamic]
deriving (Monoid)
So Info is a monoid, and it holds of a bunch of dynamic values, which could each be of any type at all. Eep!
So far, this is utterly scary to me. To tame it, the Info constructor is not
exported, and so the only way to create an Info is to start with mempty
and use this function:
addInfo :: (IsInfo v, Monoid v) => Info -> v -> Info
addInfo (Info l) v = Info (toDyn v : l)
The important part of that is that only allows adding values that are in
the IsInfo type class. That prevents the foot shooting associated with
dynamic types, by only allowing use of types that make sense as Info.
Otherwise arbitrary Strings etc could be passed to addInfo by accident, and
all get concated together, and that would be a total dynamic programming
mess.
Anything you can add into an Info, you can get back out:
getInfo :: (IsInfo v, Monoid v) => Info -> v
getInfo (Info l) = mconcat (mapMaybe fromDynamic (reverse l))
Only monoids can be stored in Info, so if you ask for a type that an Info
doesn't contain, you'll get back mempty.
Crucially, IsInfo is an open type class. Any module in Propellor
can make a new data type and make it an instance of IsInfo, and then that
new data type can be stored in the Info of a Property, and any Host that
uses the Property will have that added to its Info, available for later
introspection.
For example, this weekend I'm extending Propellor to have controllers:
Hosts that are responsible for running Propellor on some other hosts.
Useful if you want to run propellor once and have it update the
configuration of an entire network of hosts.
There can be whole chains of controllers controlling other controllers etc.
The problem is, what if host foo has the property controllerFor bar
and host bar has the property controllerFor foo? I want to avoid
a loop of foo running Propellor on bar, running Propellor on foo, ...
To detect such loops, each Host's Info should contain a list of the Hosts it's controlling. Which is not hard to accomplish:
newtype Controlling = Controlled [Host]
deriving (Typeable, Monoid)
isControlledBy :: Host -> Controlling -> Bool
h `isControlledBy` (Controlled hs) = any (== hostName h) (map hostName hs)
instance IsInfo Controlling where
propigateInfo _ = True
mkControllingInfo :: Host -> Info
mkControllingInfo controlled = addInfo mempty (Controlled [controlled])
getControlledBy :: Host -> Controlling
getControlledBy = getInfo . hostInfo
isControllerLoop :: Host -> Host -> Bool
isControllerLoop controller controlled = go S.empty controlled
where
go checked h
| controller `isControlledBy` c = True
-- avoid checking loops that have been checked before
| hostName h `S.member` checked = False
| otherwise = any (go (S.insert (hostName h) checked)) l
where
c@(Controlled l) = getControlledBy h
This is all internal to the module that needs it; the rest of propellor doesn't need to know that the Info is using used for this. And yet, the necessary information about Hosts is gathered as propellor runs.
So, that's a useful technique. I do wonder if I could somehow make
addInfo combine together values in the list that have the same type;
as it is the list can get long. And, to show Info, the best I could do was
this:
instance Show Info where
show (Info l) = "Info " ++ show (map dynTypeRep l)
The resulting long list of the types of vales stored in a host's info is not
a useful as it could be. Of course, getInfo can be used to get any
particular type of value:
*Main> hostInfo kite
Info [InfoVal System,PrivInfo,PrivInfo,Controlling,DnsInfo,DnsInfo,DnsInfo,AliasesInfo, ...
*Main> getInfo (hostInfo kite) :: AliasesInfo
AliasesInfo (fromList ["downloads.kitenet.net","git.joeyh.name","imap.kitenet.net","nntp.olduse.net" ...
And finally, I keep trying to think of a better name than "Info".
It's 2004 and I'm in Oldenburg DE, working on the Debian Installer. Colin and I pair program on partman, its new partitioner, to get it into shape. We've somewhat reluctantly decided to use it. Partman is in some ways a beautful piece of work, a mass of semi-object-oriented, super extensible shell code that sprang fully formed from the brow of Anton. And in many ways, it's mad, full of sector alignment twiddling math implemented in tens of thousands of lines of shell script scattered amoung hundreds of tiny files that are impossible to keep straight. In the tiny Oldenburg Developers Meeting, full of obscure hardware and crazy intensity of ideas like porting Debian to VAXen, we hack late into the night, night after night, and crash on the floor.

It's 2015 and I'm at a Chinese bakery, then at the Berkeley pier, then in a SF food truck lot, catching half an hour here and there in my vacation to add some features to Propellor. Mostly writing down data types for things like filesystem formats, partition layouts, and then some small amount of haskell code to use them in generic ways. Putting these peices together and reusing stuff already in Propellor (like chroot creation).
Before long I have this, which is only 2 undefined functions away from (probably) working:
let chroot d = Chroot.debootstrapped (System (Debian Unstable) "amd64") mempty d
& Apt.installed ["openssh-server"]
& ...
partitions = fitChrootSize MSDOS
[ (Just "/boot", mkPartiton EXT2)
, (Just "/", mkPartition EXT4)
, (Nothing, const (mkPartition LinuxSwap (MegaBytes 256)))
]
in Diskimage.built chroot partitions (grubBooted PC)
This is at least a replication of vmdebootstrap, generating a bootable disk image from that config and 400 lines of code, with enormous customizability of the disk image contents, using all the abilities of Propellor. But is also, effectively, a replication of everything partman is used for (aside from UI and RAID/LVM).

What a difference a decade and better choices of architecture make! In many ways, this is the loosely coupled, extensible, highly configurable system partman aspired to be. Plus elegance. And I'm writing it on a lark, because I have some spare half hours in my vacation.
Past Debian Installer team lead Tollef stops by for lunch, I show him the code, and we have the conversation old d-i developers always have about partman.
I can't say that partman was a failure, because it's been used by millions to install Debian and Ubuntu and etc for a decade. Anything that deletes that many Windows partitions is a success. But it's been an unhappy success. Nobody has ever had a good time writing partman recipes; the code has grown duplication and unmaintainability.
I can't say that these extensions to Propellor will be a success; there's no plan here to replace Debian Installer (although with a few hundred more lines of code, propellor is d-i 2.0); indeed I'm just adding generic useful stuff and building further stuff out of it without any particular end goal. Perhaps that's the real difference.
Since July, I have been aware of an ugly problem with propellor. Certain propellor configurations could have a bug. I've tried to solve the problem at least a half-dozen times without success; it's eaten several weekends.
Today I finally managed to fix propellor so it's impossible to write code that has the bug, bending the Haskell type checker to my will with the power of GADTs and type-level functions.
the bug
Code with the bug looked innocuous enough. Something like this:
foo :: Property
foo = property "foo" $
unlessM (liftIO $ doesFileExist "/etc/foo") $ do
bar <- liftIO $ readFile "/etc/foo.template"
ensureProperty $ setupFoo bar
The problem comes about because some properties in propellor have Info associated with them. This is used by propellor to introspect over the properties of a host, and do things like set up DNS, or decrypt private data used by the property.
At the same time, it's useful to let a Property internally decide to
run some other Property. In the example above, that's the ensureProperty
line, and the setupFoo Property is run only sometimes, and is
passed data that is read from the filesystem.
This makes it very hard, indeed probably impossible for Propellor to
look inside the monad, realize that setupFoo is being used, and add
its Info to the host.
Probably, setupFoo doesn't have Info associated with it -- most
properties do not. But, it's hard to tell, when writing such a Property
if it's safe to use ensureProperty. And worse, setupFoo could later
be changed to have Info.
Now, in most languages, once this problem was noticed, the solution would
probably be to make ensureProperty notice when it's called on a Property
that has Info, and print a warning message. That's Good Enough in a sense.
But it also really stinks as a solution. It means that building propellor isn't good enough to know you have a working system; you have to let it run on each host, and watch out for warnings. Ugh, no!
the solution
This screams for GADTs. (Well, it did once I learned how what GADTs are and what they can do.)
With GADTs, Property NoInfo and Property HasInfo can be separate data
types. Most functions will work on either type (Property i) but
ensureProperty can be limited to only accept a Property NoInfo.
data Property i where
IProperty :: Desc -> ... -> Info -> Property HasInfo
SProperty :: Desc -> ... -> Property NoInfo
data HasInfo
data NoInfo
ensureProperty :: Property NoInfo -> Propellor Result
Then the type checker can detect the bug, and refuse to compile it.
Yay!
Except ...
Property combinators
There are a lot of Property combinators in propellor. These combine
two or more properties in various ways. The most basic one is requires,
which only runs the first Property after the second one has successfully
been met.
So, what's it's type when used with GADT Property?
requires :: Property i1 -> Property i2 -> Property ???
It seemed I needed some kind of type class, to vary the return type.
class Combine x y r where
requires :: x -> y -> r
Now I was able to write 4 instances of Combines, for each combination
of 2 Properties with HasInfo or NoInfo.
It type checked. But, type inference was busted. A simple expression like
foo `requires` bar
blew up:
No instance for (Requires (Property HasInfo) (Property HasInfo) r0)
arising from a use of `requires'
The type variable `r0' is ambiguous
Possible fix: add a type signature that fixes these type variable(s)
Note: there is a potential instance available:
instance Requires
(Property HasInfo) (Property HasInfo) (Property HasInfo)
-- Defined at Propellor/Types.hs:167:10
To avoid that, it needed ":: Property HasInfo" appended -- I didn't want the user to need to write that.
I got stuck here for an long time, well over a month.
type level programming
Finally today I realized that I could fix this with a little type-level programming.
class Combine x y where
requires :: x -> y -> CombinedType x y
Here CombinedType is a type-level function, that calculates the type that
should be used for a combination of types x and y. This turns out to be really
easy to do, once you get your head around type level functions.
type family CInfo x y
type instance CInfo HasInfo HasInfo = HasInfo
type instance CInfo HasInfo NoInfo = HasInfo
type instance CInfo NoInfo HasInfo = HasInfo
type instance CInfo NoInfo NoInfo = NoInfo
type family CombinedType x y
type instance CombinedType (Property x) (Property y) = Property (CInfo x y)
And, with that change, type inference worked again! \o/
(Bonus: I added some more intances of CombinedType for combining things like RevertableProperties, so propellor's property combinators got more powerful too.)
Then I just had to make a massive pass over all of Propellor, fixing the types of each Property to be Property NoInfo or Property HasInfo. I frequently picked the wrong one, but the type checker was able to detect and tell me when I did.
A few of the type signatures got slightly complicated, to provide the type checker with sufficient proof to do its thing...
before :: (IsProp x, Combines y x, IsProp (CombinedType y x)) => x -> y -> CombinedType y x
before x y = (y `requires` x) `describe` (propertyDesc x)
onChange
:: (Combines (Property x) (Property y))
=> Property x
=> Property y
=> CombinedType (Property x) (Property y)
onChange = -- 6 lines of code omitted
fallback :: (Combines (Property p1) (Property p2)) => Property p1 -> Property p2 -> Property (CInfo p1 p2)
fallback = -- 4 lines of code omitted
.. This mostly happened in property combinators, which is an acceptable tradeoff, when you consider that the type checker is now being used to prove that propellor can't have this bug.
Mostly, things went just fine. The only other annoying thing was that some
things use a [Property], and since a haskell list can only contain a
single type, while Property Info and Property NoInfo are two different
types, that needed to be dealt with. Happily, I was able to extend
propellor's existing (&) and (!) operators to work in this situation,
so a list can be constructed of properties of several different types:
propertyList "foos" $ props
& foo
& foobar
! oldfoo
conclusion
The resulting 4000 lines of changes will be in the next release of propellor. Just as soon as I test that it always generates the same Info as before, and perhaps works when I run it. (eep)
These uses of GADTs and type families are not new; this is merely the first time I used them. It's another Haskell leveling up for me.
Anytime you can identify a class of bugs that can impact a complicated code base, and rework the code base to completely avoid that class of bugs, is a time to celebrate!
You have a machine someplace, probably in The Cloud, and it has Linux installed, but not to your liking. You want to do a clean reinstall, maybe switching the distribution, or getting rid of the cruft. But this requires running an installer, and it's too difficult to run d-i on remote machines.
Wouldn't it be nice if you could point a program at that machine and have it do a reinstall, on the fly, while the machine was running?
This is what I've now taught propellor to do! Here's a working configuration which will make propellor convert a system running Fedora (or probably many other Linux distros) to Debian:
testvm :: Host
testvm = host "testvm.kitenet.net"
& os (System (Debian Unstable) "amd64")
& OS.cleanInstallOnce (OS.Confirmed "testvm.kitenet.net")
`onChange` propertyList "fixing up after clean install"
[ User.shadowConfig True
, OS.preserveRootSshAuthorized
, OS.preserveResolvConf
, Apt.update
, Grub.boots "/dev/sda"
`requires` Grub.installed Grub.PC
]
& Hostname.sane
& Hostname.searchDomain
& Apt.installed ["linux-image-amd64"]
& Apt.installed ["ssh"]
& User.hasSomePassword "root"
And here's a video of it in action.
It was surprisingly easy to build this. Propellor already knew how to create a chroot, so from there it basically just has to move files around until the chroot takes over from the old OS.
After the cleanInstallOnce property does its thing, propellor is running inside a freshly debootstrapped Debian system. Then we just need a few more Propertites to get from there to a bootable, usable system: Install grub and the kernel, turn on shadow passwords, preserve a few config files from the old OS, etc.
It's really astounding to me how much easier this was to build than it was to build d-i. It took years to get d-i to the point of being able to install a working system. It took me a few part days to add this capability to propellor (It's 200 lines of code), and I've probably spent a total of less than 30 days total developing propellor in its entirity.
So, what gives? Why is this so much easier? There are a lot of reasons:
Technology is so much better now. I can spin up cloud VMs for testing in seconds; I use VirtualBox to restore a system from a snapshot. So testing is much much easier. The first work on d-i was done by booting real machines, and for a while I was booting them using floppies.
Propellor doesn't have a user interface. The best part of d-i is preseeding, but that was mostly an accident; when I started developing d-i the first thing I wrote was main-menu (which is invisible 99.9% of the time) and we had to develop cdebconf, and tons of other UI. Probably 90% of d-i work involves the UI. Jettisoning the UI entirely thus speeds up development enormously. And propellor's configuration file blows d-i preseeding out of the water in expressiveness and flexability.
Propellor has a much more principled design and implementation. Separating things into Properties, which are composable and reusable gives enormous leverage. Strong type checking and a powerful programming language make it much easier to develop than d-i's mess of shell scripts calling underpowered busybox commands etc. Properties often Just Work the first time they're tested.
No separate runtime. d-i runs in its own environment, which is really a little custom linux distribution. Developing linux distributions is hard. Propellor drops into a live system and runs there. So I don't need to worry about booting up the system, getting it on the network, etc etc. This probably removes another order of magnitude of complexity from propellor as compared with d-i.
This seems like the opposite of the Second System effect to me. So perhaps d-i was the second system all along?
I don't know if I'm going to take this all the way to propellor is d-i 2.0. But in theory, all that's needed now is:
- Teaching propellor how to build a bootable image, containing a live Debian system and propellor. (Yes, this would mean reimplementing debian-live, but I estimate 100 lines of code to do it in propellor; most of the Properties needed already exist.) That image would then be booted up and perform the installation.
- Some kind of UI that generates the propellor config file.
- Adding Properties to partition the disk.
cleanInstallOnce and associated Properties will be included in
propellor's upcoming 1.1.0 release, and are available in git now.
Oh BTW, you could parameterize a few Properties by OS, and Propellor could be used to install not just Debian or Ubuntu, but whatever Linux distribution you want. Patches welcomed...
Propellor has supported docker containers for a "long" time, and it works great. This week I've worked on adding more container support.
docker containers (revisited)
The syntax for docker containers has changed slightly. Here's how it looks now:
example :: Host
example = host "example.com"
& Docker.docked webserverContainer
webserverContainer :: Docker.Container
webserverContainer = Docker.container "webserver" (Docker.latestImage "joeyh/debian-stable")
& os (System (Debian (Stable "wheezy")) "amd64")
& Docker.publish "80:80"
& Apt.serviceInstalledRunning "apache2"
& alias "www.example.com"
That makes example.com have a web server in a docker container, as you'd expect, and when propellor is used to deploy the DNS server it'll automatically make www.example.com point to the host (or hosts!) where this container is docked.
I use docker a lot, but I have drank little of the Docker KoolAid. I'm not keen on using random blobs created by random third parties using either unreproducible methods, or the weirdly underpowered dockerfiles. (As for vast complicated collections of containers that each run one program and talk to one another etc ... I'll wait and see.)
That's why propellor runs inside the docker container and deploys whatever configuration I tell it to, in a way that's both replicatable later and lets me use the full power of Haskell.
Which turns out to be useful when moving on from docker containers to something else...
systemd-nspawn containers
Propellor now supports containers using systemd-nspawn. It looks a lot like the docker example.
example :: Host
example = host "example.com"
& Systemd.persistentJournal
& Systemd.nspawned webserverContainer
webserverContainer :: Systemd.Container
webserverContainer = Systemd.container "webserver" chroot
& Apt.serviceInstalledRunning "apache2"
& alias "www.example.com"
where
chroot = Chroot.debootstrapped (System (Debian Unstable) "amd64") Debootstrap.MinBase
Notice how I specified the Debian Unstable chroot that forms the basis of this container. Propellor sets up the container by running debootstrap, boots it up using systemd-nspawn, and then runs inside the container to provision it.
Unlike docker containers, systemd-nspawn containers use systemd as their
init, and it all integrates rather beautifully. You can see the container
listed in systemctl status, including the services running inside it,
use journalctl to examine its logs, etc.
But no, systemd is the devil, and docker is too trendy...
chroots
Propellor now also supports deploying good old chroots. It looks a lot like the other containers. Rather than repeat myself a third time, and because we don't really run webservers inside chroots much, here's a slightly different example.
example :: Host
example = host "mylaptop"
& Chroot.provisioned (buildDepChroot "git-annex")
buildDepChroot :: Apt.Package -> Chroot.Chroot
buildDepChroot pkg = Chroot.debootstrapped system Debootstrap.BuildD dir
& Apt.buildDep pkg
where
dir = /srv/chroot/builddep/"++pkg
system = System (Debian Unstable) "amd64"
Again this uses debootstrap to build the chroot, and then it runs propellor inside the chroot to provision it (btw without bothering to install propellor there, thanks to the magic of bind mounts and completely linux distribution-independent packaging).
In fact, the systemd-nspawn container code reuses the chroot code, and so turns out to be really rather simple. 132 lines for the chroot support, and 167 lines for the systemd support (which goes somewhat beyond the nspawn containers shown above).
Which leads to the hardest part of all this...
debootstrap
Making a propellor property for debootstrap should be easy. And it was, for Debian systems. However, I have crazy plans that involve running propellor on non-Debian systems, to debootstrap something, and installing debootstrap on an arbitrary linux system is ... too hard.
In the end, I needed 253 lines of code to do it, which is barely one magnitude less code than the size of debootstrap itself. I won't go into the ugly details, but this could be made a lot easier if debootstrap catered more to being used outside of Debian.
closing
Docker and systemd-nspawn have different strengths and weaknesses, and there are sure to be more container systems to come. I'm pleased that Propellor can add support for a new container system in a few hundred lines of code, and that it abstracts away all the unimportant differences between these systems.
PS
Seems likely that systemd-nspawn containers can be nested to any depth. So, here's a new kind of fork bomb!
infinitelyNestedContainer :: Systemd.Container
infinitelyNestedContainer = Systemd.container "evil-systemd"
(Chroot.debootstrapped (System (Debian Unstable) "amd64") Debootstrap.MinBase)
& Systemd.nspawned infinitelyNestedContainer
Strongly typed purely functional container deployment can only protect us against a certian subset of all badly thought out systems. ;)
Note that the above was written in 2014 and some syntatix details have changed. See the documentation for Propellor.Property.Chroot, Propellor.Property.Debootstrap, Propellor.Property.Docker, Propellor.Property.Systemd for current examples.
Today I did something interesting with the Debian packaging for propellor, which seems like it could be a useful technique for other Debian packages as well.
Propellor is configured by a directory, which is maintained as a local git
repository. In propellor's case, it's ~/.propellor/. This contains a lot
of haskell files, in fact the entire source code of propellor! That's
really unusual, but I think this can be generalized to any package whose
configuration is maintained in its own git repository on the user's
system. For now on, I'll refer to this as the config repo.
The config repo is set up the first time a user runs propellor. But, until now, I didn't provide an easy way to update the config repo when the propellor package was updated. Nothing would break, but the old version would be used until the user updated it themselves somehow (probably by pulling from a git repository over the network, bypassing apt's signature validation).
So, what I wanted was a way to update the config repo, merging in any
changes from the new version of the Debian package, while preserving the
user's local modifications. Ideally, the user could just run git merge
upstream/master, where the upstream repo was included in the
Debian package.
But, that can't work! The Debian package can't reasonably include the full git repository of propellor with all its history. So, any git repository included in the Debian binary package would need to be a synthetic one, that only contains probably one commit that is not connected to anything else. Which means that if the config repo was cloned from that repo in version 1.0, then when version 1.1 came around, git would see no common parent when merging 1.1 into the config repo, and the merge would fail horribly.
To solve this, let's assume that the config repo's master branch has
a parent commit that can be identified, somehow, as coming from a past
version of the Debian package. It doesn't matter which version, although
the last one merged with will be best. (The easy way to do this is to set
refs/heads/upstream/master to point to it when creating the config repo.)
Once we have that parent commit, we have three things:
- The current content of the config repo.
- The content from some old version of the Debian package.
- The new content of the Debian package.
Now git can be used to merge #3 onto #2, with -Xtheirs, so the result is a git commit with parents of #3 and #2, and content of #3. (This can be done using a temporary clone of the config repo to avoid touching its contents.)
Such a git commit can be merged into the config repo, without any conflicts other than those the user might have caused with their own edits.
So, propellor will tell the user when updates are available, and they can
simply run git merge upstream/master to get them. The resulting history
looks like this:
* Merge remote-tracking branch 'upstream/master' |\ | * merging upstream version | |\ | | * upstream version * | user change |/ * upstream version
So, generalizing this, if a package has a lot of config files, and creates a git repository containing them when the user uses it (or automatically when it's installed), this method can be used to provide an easily mergable branch that tracks the files as distributed with the package.
It would perhaps not be hard to get from here to a full git-backed version of ucf. Note that the Debian binary package doesn't have to ship a git repisitory, it can just as easily ship the current version of the config files somewhere in /usr, and check them into a new empty repository as part of the generation of the upstream/master branch.
I wrote my own init. I didn't mean to, and in the end, it took 2 lines of
code. Here's how.
Propellor has the nice feature of supporting provisioning of Docker containers. Since Docker normally runs just one command inside the container, I made the command that docker runs be propellor, which runs inside the container and takes care of provisioning it according to its configuration.
For example, here's a real live configuration of a container:
-- Exhibit: kite's 90's website.
, standardContainer "ancient-kitenet" Stable "amd64"
& Docker.publish "1994:80"
& Apt.serviceInstalledRunning "apache2"
& Git.cloned "root" "git://kitenet-net.branchable.com/" "/var/www"
(Just "remotes/origin/old-kitenet.net")
When propellor is run inside this container, it takes care of installing apache, and since the property states apache should be running, it also starts the daemon if necessary.
At boot, docker remembers the command that was used to start the container last time, and runs it again. This time, apache is already installed, so propellor simply starts the daemon.
This was surprising, but it was just what I wanted too! The only missing bit to make this otherwise entirely free implementation of init work properly was two lines of code:
void $ async $ job reapzombies
where
reapzombies = void $ getAnyProcessStatus True False
Propellor-as-init also starts up a simple equalivilant of rsh on a named pipe (for communication between the propellor inside and outside the container), and also runs a root login shell (so the user can attach to the container and administer it). Also, running a compiled program from the host system inside a container, which might use a different distribution or architecture was an interesting challenge (solved using the method described in completely linux distribution-independent packaging). So it wasn't entirely trivial, but as far as init goes, it's probably one of the simpler implementations out there.
I know that there are various other solutions on the space of an init for
Docker -- personally I'd rather the host's systemd integrated with it
so I could see the status of the container's daemons in systemctl status.
If that does happen, perhaps I'll eventually be able to remove 2 lines of code
from propellor.
Took a while to get here, but Propellor 0.4.0 can deploy DNS servers and I just had it deploy mine. Including generating DNS zone files.
Configuration is dead simple, as far as DNS goes:
& alias "ns1.example.com"
& Dns.secondary hosts "joeyh.name"
& Dns.primary hosts "example.com"
(Dns.mkSOA "ns1.example.com" 100)
[ (RootDomain, NS $ AbsDomain "ns1.example.com")
, (RootDomain, NS $ AbsDomain "ns2.example.com")
]
The awesome thing is that propellor fills in all the other information in the zone file by looking at the properties of the hosts it knows about.
, host "blue.example.com"
& ipv4 "192.168.1.1"
& ipv6 "fe80::26fd:52ff:feea:2294"
& alias "example.com"
& alias "www.example.com"
& alias "example.museum"
& Docker.docked hosts "webserver"
`requres` backedup "/var/www"
& alias "ns2.example.com"
& Dns.secondary hosts "example.com"
When it sees this host, Propellor adds its IP addresses to the example.com DNS zone file, for both its main hostname ("blue.example.com"), and also its relevant aliases. (The .museum alias would go into a different zone file.)
Multiple hosts can define the same alias, and then you automaticlly get round-robin DNS.
The web server part of of the blue.example.com config can be cut and pasted to another host in order to move its web server to the other host, including updating the DNS. That's really all there is to is, just cut, paste, and commit!
I'm quite happy with how that worked out. And curious if Puppet etc have anything similar.
One tricky part of this was how to ensure that the serial number automtically updates when changes are made. The way this is handled is Propellor starts with a base serial number (100 in the example above), and then it adds to it the number of commits in its git repository. The zone file is only updated when something in it besides the serial number needs to change.
The result is nice small serial numbers that don't risk overflowing the (so 90's) 32 bit limit, and will be consistent even if the configuration had Propellor setting up multiple independent master DNS servers for the same domain.
Another recent feature in Propellor is that it can use Obnam to back up a directory. With the awesome feature that if the backed up directory is empty/missing, Propellor will automcatically restore it from the backup.
Here's how the backedup property used in the example above
might be implemented:
backedup :: FilePath -> Property
backedup dir = Obnam.backup dir daily
[ "--repository=sftp://rsync.example.com/~/webserver.obnam"
] Obnam.OnlyClient
`requires` Ssh.keyImported SshRsa "root"
`requires` Ssh.knownHost hosts "rsync.example.com" "root"
`requires` Gpg.keyImported "1B169BE1" "root"
Notice that the Ssh.knownHost makes root trust the ssh host key
belonging to rsync.example.com. So Propellor needs to be told what that
host key is, like so:
, host "rsync.example.com"
& ipv4 "192.168.1.4"
& sshPubKey "ssh-rsa blahblahblah"
Which of course ties back into the DNS and gets this hostname set in it. But also, the ssh public key is available for this host and visible to the DNS zone file generator, and that could also be set in the DNS, in a SSHFP record. I haven't gotten around to implementing that, but hope at some point to make Propellor support DNSSEC, and then this will all combine even more nicely.
By the way, Propellor is now up to 3 thousand lines of code (not including Utility library). In 20 days, as a 10% time side project.
In just released Propellor 0.3.0, I've improved improved Propellor's config file DSL significantly. Now properties can set attributes of a host, that can be looked up by its other properties, using a Reader monad.
This saves needing to repeat yourself:
hosts = [ host "orca.kitenet.net"
& stdSourcesList Unstable
& Hostname.sane -- uses hostname from above
And it simplifies docker setup, with no longer a need to differentiate between properties that configure docker vs properties of the container:
-- A generic webserver in a Docker container.
, Docker.container "webserver" "joeyh/debian-unstable"
& Docker.publish "80:80"
& Docker.volume "/var/www:/var/www"
& Apt.serviceInstalledRunning "apache2"
But the really useful thing is, it allows automating DNS zone file creation, using attributes of hosts that are set and used alongside their other properties:
hosts =
[ host "clam.kitenet.net"
& ipv4 "10.1.1.1"
& cname "openid.kitenet.net"
& Docker.docked hosts "openid-provider"
& cname "ancient.kitenet.net"
& Docker.docked hosts "ancient-kitenet"
, host "diatom.kitenet.net"
& Dns.primary "kitenet.net" hosts
]
Notice that hosts is passed into Dns.primary, inside the definition
of hosts! Tying the knot like this is a fun haskell laziness trick. :)
Now I just need to write a little function to look over the hosts and generate a zone file from their hostname, cname, and address attributes:
extractZoneFile :: Domain -> [Host] -> ZoneFile
extractZoneFile = gen . map hostAttr
where gen = -- TODO
The eventual plan is that the cname property won't be defined as a
property of the host, but of the container running inside it.
Then I'll be able to cut-n-paste move docker containers between hosts,
or duplicate the same container onto several hosts to deal with load,
and propellor will provision them, and update the zone file appropriately.
Also, Chris Webber had suggested that Propellor be able to separate values from properties, so that eg, a web wizard could configure the values easily. I think this gets it much of the way there. All that's left to do is two easy functions:
overrideAttrsFromJSON :: Host -> JSON -> Host
exportJSONAttrs :: Host -> JSON
With these, propellor's configuration could be adjusted at run time using JSON from a file or other source. For example, here's a containerized webserver that publishes a directory from the external host, as configured by JSON that it exports:
demo :: Host
demo = Docker.container "webserver" "joeyh/debian-unstable"
& Docker.publish "80:80"
& dir_to_publish "/home/mywebsite" -- dummy default
& Docker.volume (getAttr dir_to_publish ++":/var/www")
& Apt.serviceInstalledRunning "apache2"
main = do
json <- readJSON "my.json"
let demo' = overrideAttrsFromJSON demo
writeJSON "my.json" (exportJSONAttrs demo')
defaultMain [demo']
Propellor ensures that a list of properties about a system are satisfied. But requirements change, and so you might want to revert a property that had been set up before.
For example, I had a system with a webserver container:
Docker.docked container hostname "webserver"
I don't want a web server there any more. Rather than having a separate property to stop it, wouldn't it be nice to be able to say:
revert (Docker.docked container hostname "webserver")
I've now gotten this working. The really fun part is, some properies support reversion, but other properties certianly do not. Maybe the code to revert them is not worth writing, or maybe the property does something that cannot be reverted.
For example, Docker.garbageCollected is a property that makes sure there
are no unused docker images wasting disk space. It can't be reverted.
Nor can my personal standardSystem Unstable property, which amoung other
things upgrades the system to unstable and sets up my home directory..
I found a way to make Propellor statically check if a property can be
reverted at compile time. So revert Docker.garbageCollected will fail
to type check!
The tricky part about implementing this is that the user configures Propellor with a list of properties. But now there are two distinct types of properties, revertable ones and non-revertable ones. And Haskell does not support heterogeneous lists..
My solution to this is a typeclass and some syntactic sugar operators. To build a list of properties, with individual elements that might be revertable, and others not:
props
& standardSystem Unstable
& revert (Docker.docked container hostname "webserver")
& Docker.docked container hostname "amd64-git-annex-builder"
& Docker.garbageCollected
Propellor development is churning away! (And leaving no few puns in its wake..)
Now it supports secure handling of private data like passwords (only the host that owns it can see it), and fully end-to-end secured deployment via gpg signed and verified commits.
And, I've just gotten support for Docker to build. Probably not quite work, but it should only be a few bugs away at this point.
Here's how to deploy a dockerized webserver with propellor:
host hostname@"clam.kitenet.net" = Just
[ Docker.configured
, File.dirExists "/var/www"
, Docker.hasContainer hostname "webserver" container
]
container _ "webserver" = Just $ Docker.containerFromImage "joeyh/debian-unstable"
[ Docker.publish "80:80"
, Docker.volume "/var/www:/var/www"
, Docker.inside
[ serviceRunning "apache2"
`requires` Apt.installed ["apache2"]
]
]
Docker containers are set up using Properties too, just like regular hosts, but their Properties are run inside the container.
That means that, if I change the web server port above, Propellor will notice the container config is out of date, and stop the container, commit an image based on it, and quickly use that to bring up a new container with the new configuration.
If I change the web server to say, lighttpd, Propellor will run inside the container, and notice that it needs to install lighttpd to satisfy the new property, and so will update the container without needing to take it down.
Adding all this behavior took only 253 lines of code, and none of it impacts the core of Propellor at all; it's all in Propellor.Property.Docker. (Well, I did need another hundred lines to write a daemon that runs inside the container and reads commands to run over a named pipe... Docker makes running ad-hoc commands inside a container a PITA.)
So, I think that this vindicates the approach of making the configuration of Propellor be a list of Properties, which can be constructed by abitrarily interesting Haskell code. I didn't design Propellor to support containers, but it was easy to find a way to express them as shown above.
Compare that with how Puppet supports Docker: http://docs.docker.io/en/latest/use/puppet/
docker::run { 'helloworld':
image => 'ubuntu',
command => '/bin/sh -c "while true; do echo hello world; sleep 1; done"',
ports => ['4444', '4555'],
...
All puppet manages is running the image and a simple static command inside it. All the complexities that puppet provides for configuring servers cannot easily be brought to bear inside the container, and a large reason for that is, I think, that its configuration file is just not expressive enough.
Whups, I seem to have built a configuration management system this evening!
Propellor has similar goals to chef or puppet or ansible, but with an approach much more like slaughter. Except it's configured by writing Haskell code.
The name is because propellor ensures that a system is configured with the desired PROPerties, and also because it kind of pulls system configuration along after it. And you may not want to stand too close.
Disclaimer: I'm not really a sysadmin, except for on the scale of "diffuse administration of every Debian machine on planet earth or nearby", and so I don't really understand configuration management. (Well, I did write debconf, which claims to be the "Debian Configuration Management system".. But I didn't understand configuration management back then either.)
So, propellor makes some perhaps wacky choices. The least of these is that it's built from a git repository that any (theoretical) other users will fork and modify; a cron job can re-make it from time to time and pull down configuration changes, or something can be run to push changes.
A really simple configuration for a Tor bridge server using propellor looks something like this:
main = ensureProperties
[ Apt.stdSourcesList Apt.Stable `onChange` Apt.upgrade
, Apt.removed ["exim4"] `onChange` Apt.autoRemove
, Hostname.set "bridget"
, Ssh.uniqueHostKeys
, Tor.isBridge
]
Since it's just haskell code, it's "easy" to refactor out common configurations for classes of servers, etc. Or perhaps integrate reclass? I don't know. I'm happy with just pure functions and type-safe refactorings of my configs, I think.
Properties are also written in Haskell of course. This one ensures that all the packages in a list are installed.
installed :: [Package] -> Property
installed ps = check (isInstallable ps) go
where
go = runApt $ [Param "-y", Param "install"] ++ map Param ps
Here's one that ensures the hostname is set to the desired value, which shows how to specify content for a file, and also how to run another action if a change needed to be made to satisfy a property.
set :: HostName -> Property
set hostname = "/etc/hostname" `File.hasContent` [hostname]
`onChange` cmdProperty "hostname" [Param hostname]
Here's part of a custom one that I use to check out a user's home directory from git. Shows how to make a property require that some other property is satisfied first, and how to test if a property has already been satisfied.
installedFor :: UserName -> Property
installedFor user = check (not <$> hasGitDir user) $
Property ("githome " ++ user) (go =<< homedir user)
`requires` Apt.installed ["git", "myrepos"]
where
go ... -- 12 lines elided
I'm about 37% happy with the overall approach to listing properties and combining properties into larger properties etc. I think that some unifying insight is missing -- perhaps there should be a Property monad? But as long as it yields a list of properties, any smarter thing should be able to be built on top of this.
Propellor is 564 lines of code, including 25 or so built-in properties like the examples above. It took around 4 hours to build.
I'm pretty sure it was easier to write it than it would have been to look into ansible and salt and slaughter (and also liw's human-readable configuration language whose name I've forgotten) in enough detail to pick one, and learn how its configuration worked, and warp it into something close to how I wanted this to work.
I think that's interesting.. It's partly about NIH and I-want-everything-in-Haskell, but it's also about a complicated system that is a lot of things to a lot of people -- of the kind I see when I look at ansible -- vs the tools and experience to build just the thing you want without the cruft. Nice to have the latter!