I've been doing a little bit of dynamically typed programming in Haskell,
to improve Propellor's Info type. The result is kind of
interesting in a scary way.
Info started out as a big record type, containing all the different sorts
of metadata that Propellor needed to keep track of. Host IP addresses, DNS
entries, ssh public keys, docker image configuration parameters... This got
quite out of hand. Info needed to have its hands in everything,
even types that should have been private to their module.
To fix that, recent versions of Propellor let a single
Info contain many different types of values. Look at it one way and
it contains DNS entries; look at it another way and it contains ssh public
keys, etc.
As an émigré from lands where you can never know what type of value is in
a $foo until you look, this was a scary prospect at first, but I found
it's possible to have the benefits of dynamic types and the safety of
static types too.
The key to doing it is Data.Dynamic. Thanks to Joachim Breitner for
suggesting I could use it here. What I arrived at is this type (slightly
simplified):
newtype Info = Info [Dynamic]
deriving (Monoid)
So Info is a monoid, and it holds of a bunch of dynamic values, which could each be of any type at all. Eep!
So far, this is utterly scary to me. To tame it, the Info constructor is not
exported, and so the only way to create an Info is to start with mempty
and use this function:
addInfo :: (IsInfo v, Monoid v) => Info -> v -> Info
addInfo (Info l) v = Info (toDyn v : l)
The important part of that is that only allows adding values that are in
the IsInfo type class. That prevents the foot shooting associated with
dynamic types, by only allowing use of types that make sense as Info.
Otherwise arbitrary Strings etc could be passed to addInfo by accident, and
all get concated together, and that would be a total dynamic programming
mess.
Anything you can add into an Info, you can get back out:
getInfo :: (IsInfo v, Monoid v) => Info -> v
getInfo (Info l) = mconcat (mapMaybe fromDynamic (reverse l))
Only monoids can be stored in Info, so if you ask for a type that an Info
doesn't contain, you'll get back mempty.
Crucially, IsInfo is an open type class. Any module in Propellor
can make a new data type and make it an instance of IsInfo, and then that
new data type can be stored in the Info of a Property, and any Host that
uses the Property will have that added to its Info, available for later
introspection.
For example, this weekend I'm extending Propellor to have controllers:
Hosts that are responsible for running Propellor on some other hosts.
Useful if you want to run propellor once and have it update the
configuration of an entire network of hosts.
There can be whole chains of controllers controlling other controllers etc.
The problem is, what if host foo has the property controllerFor bar
and host bar has the property controllerFor foo? I want to avoid
a loop of foo running Propellor on bar, running Propellor on foo, ...
To detect such loops, each Host's Info should contain a list of the Hosts it's controlling. Which is not hard to accomplish:
newtype Controlling = Controlled [Host]
deriving (Typeable, Monoid)
isControlledBy :: Host -> Controlling -> Bool
h `isControlledBy` (Controlled hs) = any (== hostName h) (map hostName hs)
instance IsInfo Controlling where
propigateInfo _ = True
mkControllingInfo :: Host -> Info
mkControllingInfo controlled = addInfo mempty (Controlled [controlled])
getControlledBy :: Host -> Controlling
getControlledBy = getInfo . hostInfo
isControllerLoop :: Host -> Host -> Bool
isControllerLoop controller controlled = go S.empty controlled
where
go checked h
| controller `isControlledBy` c = True
-- avoid checking loops that have been checked before
| hostName h `S.member` checked = False
| otherwise = any (go (S.insert (hostName h) checked)) l
where
c@(Controlled l) = getControlledBy h
This is all internal to the module that needs it; the rest of propellor doesn't need to know that the Info is using used for this. And yet, the necessary information about Hosts is gathered as propellor runs.
So, that's a useful technique. I do wonder if I could somehow make
addInfo combine together values in the list that have the same type;
as it is the list can get long. And, to show Info, the best I could do was
this:
instance Show Info where
show (Info l) = "Info " ++ show (map dynTypeRep l)
The resulting long list of the types of vales stored in a host's info is not
a useful as it could be. Of course, getInfo can be used to get any
particular type of value:
*Main> hostInfo kite
Info [InfoVal System,PrivInfo,PrivInfo,Controlling,DnsInfo,DnsInfo,DnsInfo,AliasesInfo, ...
*Main> getInfo (hostInfo kite) :: AliasesInfo
AliasesInfo (fromList ["downloads.kitenet.net","git.joeyh.name","imap.kitenet.net","nntp.olduse.net" ...
And finally, I keep trying to think of a better name than "Info".
With the disclamer that I don't really know much about orchestration, I have added support for something resembling it to Propellor.
Until now, when using propellor to manage a bunch of hosts, you
updated them one at a time by running propellor --spin $somehost,
or maybe you set up a central git repository, and a cron job to run
propellor on each host, pulling changes from git.
I like both of these ways to use propellor, but they only go so far...
Perhaps you have a lot of hosts, and would like to run propellor on them all concurrently.
master = host "master.example.com" & concurrently conducts alotofhostsPerhaps you want to run propellor on your dns server last, so when you add a new webserver host, it gets set up and working before the dns is updated to point to it.
master = host "master.example.com" & conducts webservers `before` conducts dnsserverPerhaps you have something more complex, with multiple subnets that propellor can run in concurrently, finishing up by updating that dnsserver.
master = host "master.example.com" & concurrently conducts [sub1, sub2] `before` conducts dnsserver sub1 = "master.subnet1.example.com" & concurrently conducts webservers & conducts loadbalancers sub2 = "master.subnet2.example.com" & conducts dockerserversPerhaps you need to first run some command that creates a VPS host, and then want to run propellor on that host to set it up.
vpscreate h = cmdProperty "vpscreate" [hostName h] `before` conducts h
All those scenarios are supported by propellor now!
Well, I
haven't actually implemented concurrently yet,
but the point is that the conducts property can be used with any
of propellor's property combinators, like before etc,
to express all kinds of scenarios.
The conducts property works in combination with an orchestrate function
to set up all the necessary stuff to let one host ssh into another and run
propellor there.
main = defaultMain (orchestrate hosts)
hosts =
[ master
, webservers
, ...
]
The orchestrate function does a bunch of stuff:
- Builds up a graph of what conducts what.
- Removes any cycles that might have snuck in by accident, before they cause foot shooting.
- Arranges for the ssh keys to be accepted as necessary.
Note that you you need to add ssh key properties to all relevant hosts so it knows what keys to trust. - Arranges for the private data of a host to be provided to the hosts that conduct it, so they can pass it along.
I've very pleased that I was able to add the Propellor.Property.Conductor module implementing this with only a tiny change to the rest of propellor. Almost everything needed to implement it was there in propellor's infrastructure already.
Also kind of cool that it only needed 13 lines of imperative code, the other several hundred lines of the implementation being all pure code.
Following up on Then and Now ...
In quiet moments at ICFP last August, I finished teaching Propellor to generate disk images. With an emphasis on doing a whole lot with very little new code and extreme amount of code reuse.
For example, let's make a disk image with nethack on it. First, we need to define a chroot. Disk image creation reuses propellor's chroot support, described back in propelling containers. Any propellor properties can be assigned to the chroot, so it's easy to describe the system we want.
nethackChroot :: FilePath -> Chroot
nethackChroot d = Chroot.debootstrapped (System (Debian Stable) "amd64") mempty d
& Apt.installed ["linux-image-amd64"]
& Apt.installed ["nethack-console"]
& accountFor gamer
& gamer `hasInsecurePassword` "hello"
& gamer `hasLoginShell` "/usr/games/nethack"
where gamer = User "gamer"
Now to make an image from that chroot, we just have to tell propellor where to put the image file, some partitioning information, and to make it boot using grub.
nethackImage :: RevertableProperty
nethackImage = imageBuilt "/srv/images/nethack.img" nethackChroot
MSDOS (grubBooted PC)
[ partition EXT2 `mountedAt` "/boot"
`setFlag` BootFlag
, partition EXT4 `mountedAt` "/"
`addFreeSpace` MegaBytes 100
, swapPartition (MegaBytes 256)
]
The disk image partitions default to being sized to fit exactly the files
from the chroot that go into each partition, so, the disk image is as small
as possible by default. There's a little DSL to configure the partitions.
To give control over the partition size, it has some functions, like
addFreeSpace and setSize. Other functions like setFlag and
extended can further adjust the partitions. I think that worked out
rather well; the partition specification is compact and avoids unecessary
hardcoded sizes, while providing plenty of control.
By the end of ICFP, I had Propellor building complete disk images, but no boot loader installed on them.
Fast forward to today. After stuggling with some strange grub behavior, I found a working method to install grub onto a disk image.
The whole disk image feature weighs in at:
203 lines to interface with parted
88 lines to format and mount partitions
90 lines for the partition table specification DSL and partition sizing
196 lines to generate disk images
75 lines to install grub on a disk image
652 lines of code total
Which is about half the size of vmdebootstrap 1/4th the size of partman-base (probably 1/100th the size of total partman), and 1/13th the size of live-build. All of which do similar things, in ways that seem to me to be much less flexible than Propellor.
One thing I'm considering doing is extending this so Propellor can use qemu-user-static to create disk images for eg, arm. Add some u-boot setup, and this could create bootable images for arm boards. A library of configs for various arm boards could then be included in Propellor. This would be a lot easier than running the Debian Installer on an arm board.
Oh! I only just now realized that if you have a propellor host configured,
like this example for my dialup gateway, leech --
leech = host "leech.kitenet.net"
& os (System (Debian (Stable "jessie")) "armel")
& Apt.installed ["linux-image-kirkwood", "ppp", "screen", "iftop"]
& privContent "/etc/ppp/peers/provider"
& privContent "/etc/ppp/pap-secrets"
& Ppp.onBoot
& hasPassword (User "root")
& Ssh.installed
-- The host's properties can be extracted from it, using eg
hostProperties leech and reused to create a disk image with
the same properties as the host!
So, when my dialup gateway gets struck by lightning again, I could use this to build a disk image for its replacement:
import qualified Propellor.Property.Hardware.SheevaPlug as SheevaPlug
laptop = host "darkstar.kitenet.net"
& SheevaPlug.diskImage "/srv/images/leech.img" (MegaBytes 2000)
(& propertyList "has all of leech's properties"
(hostProperties leech))
This also means you can start with a manually built system, write down the properties it has, and iteratively run Propellor against it until you think you have a full specification of it, and then use that to generate a new, clean disk image. Nice way to transition from sysadmin days of yore to a clean declaratively specified system.
concurrent-output is a Haskell library I've developed this week, to make it easier to write console programs that do a lot of different things concurrently, and want to serialize concurrent outputs sanely.
It's increasingly easy to write concurrent programs, but all their status reporting has to feed back through the good old console, which is still obstinately serial.
Haskell illustrates problem this well with this "Linus's first kernel" equivilant interleaving the output of 2 threads:
> import System.IO
> import Control.Concurrent.Async
> putStrLn (repeat 'A') `concurrently` putStrLn (repeat 'B')
BABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABA
BABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABABA
...
That's fun, but also horrible if you wanted to display some messages to the user:
> putStrLn "washed the car" `concurrently` putStrLn "walked the dog"
walwkaesdh etdh et hdeo gc
ar
To add to the problem, we often want to run separate programs concurrently,
which have output of their own to display. And, just to keep things
interesting, sometimes a unix program will behave differently when stdout
is not connected to a terminal (eg, ls | cat).
To tame simple concurrent programs like these so they generate readable output involves a lot of plumbing. Something like, run the actions concurrently, taking care to capture the output of any commands, and then feed the output that the user should see though some sort of serializing channel to the display. Dealing with that when you just wanted a simple concurrent program risks ending up with a not-so-simple program.
So, I wanted an library with basically 2 functions:
outputConcurrent :: String -> IO ()
createProcessConcurrent :: CreateProcess -> IO whatever
The idea is, you make your program use outputConcurrent to display
all its output, and each String you pass to that will be displayed serially,
without getting mixed up with any other concurrent output.
And, you make your program use createProcessConcurrent everywhere it
starts a process that might output to stdout or stderr, and it'll likewise
make sure its output is displayed serially.
Oh, and createProcessConcurrent should avoid redirecting stdout and
stderr away from the console, when no other concurrent output is happening.
So, if programs are mostly run sequentially, they behave as they normally
would at the console; any behavior changes should only occur when
there is concurrency. (It might also be nice for it to allocate
ttys and run programs there to avoid any behavior changes at all,
although I have not tried to do that.)
And that should be pretty much the whole API, although it's ok if it needs some function called by main to set it up:
import Control.Concurrent.Async
import System.Console.Concurrent
import System.Process
main = withConcurrentOutput $
outputConcurrent "washed the car\n"
`concurrently`
createProcessConcurrent (proc "ls" [])
`concurrently`
outputConcurrent "walked the dog\n"
$ ./demo
washed the car
walked the dog
Maildir/ bin/ doc/ html/ lib/ mail/ mnt/ src/ tmp/
I think that's a pretty good API to deal with this concurrent output problem. Anyone know of any other attempts at this I could learn from?
I implemented this over the past 3 days and 320 lines of code. It got rather hairy:
- It has to do buffering of the output.
- There can be any quantity of output, but program memory use should be reasonably small. Solved by buffering up to 1 mb of output in RAM, and writing excess buffer to temp files.
- Falling off the end of the program is complicated; there can be buffered output to flush and it may have to wait for some processes to finish running etc.
- The locking was tough to get right! I could not have managed to write it correctly without STM.
It seems to work pretty great though. I got Propellor using it, and Propellor can now run actions concurrently!
Building on top of concurrent-output, and some related work Joachim Breitner did earlier, I now have a kind of equivilant to a tiling window manager, except it's managing regions of the console for different parts of a single program.
Here's a really silly demo, in an animated gif:
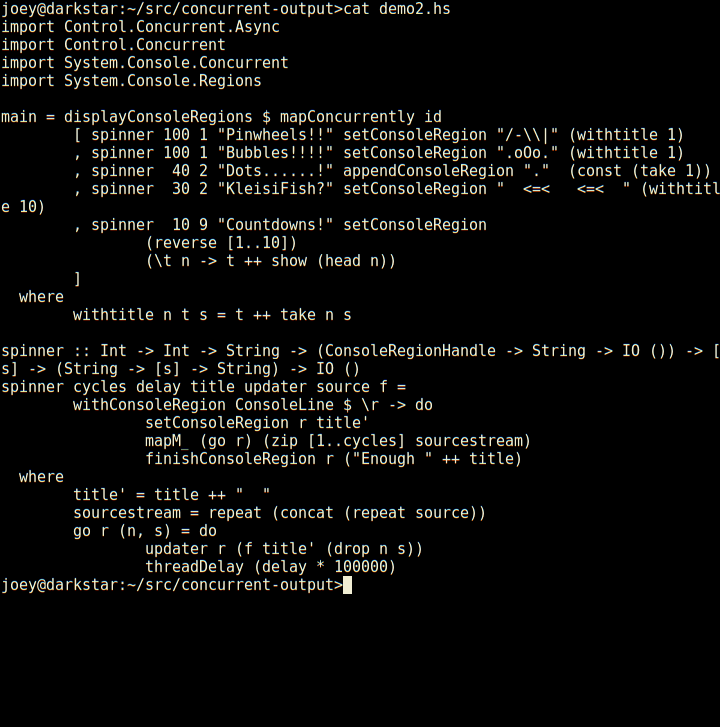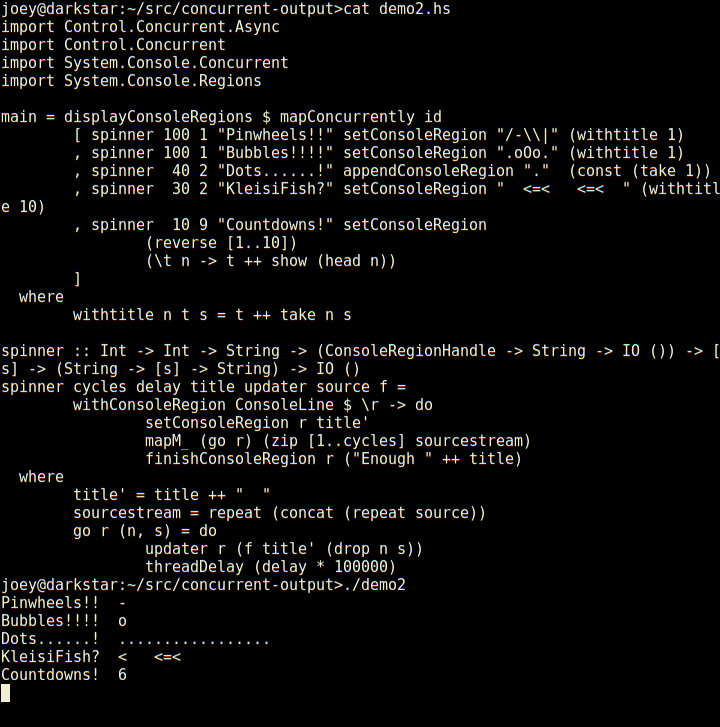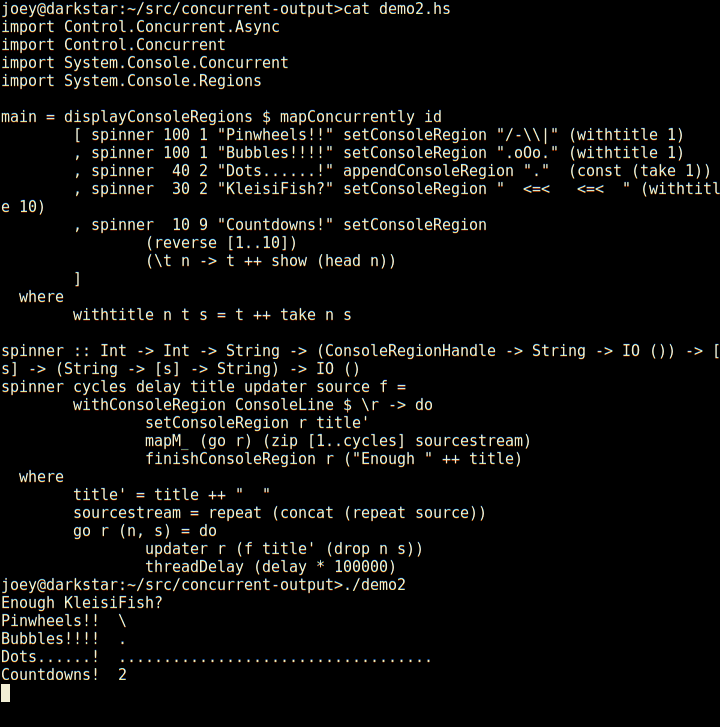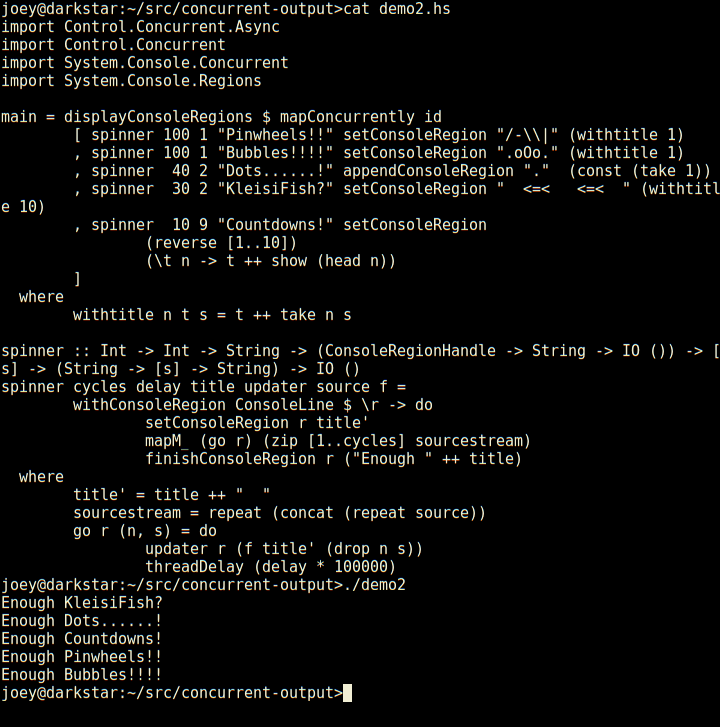
Not bad for 23 lines of code, is that? Seems much less tedious to do things this way than using ncurses. Even with its panels, ncurses requires you to think about layout of various things on the screen, and many low-level details. This, by contrast, is compositional, just add another region and a thread to update it, and away it goes.
So, here's an apt-like download progress display, in 30 lines of code.
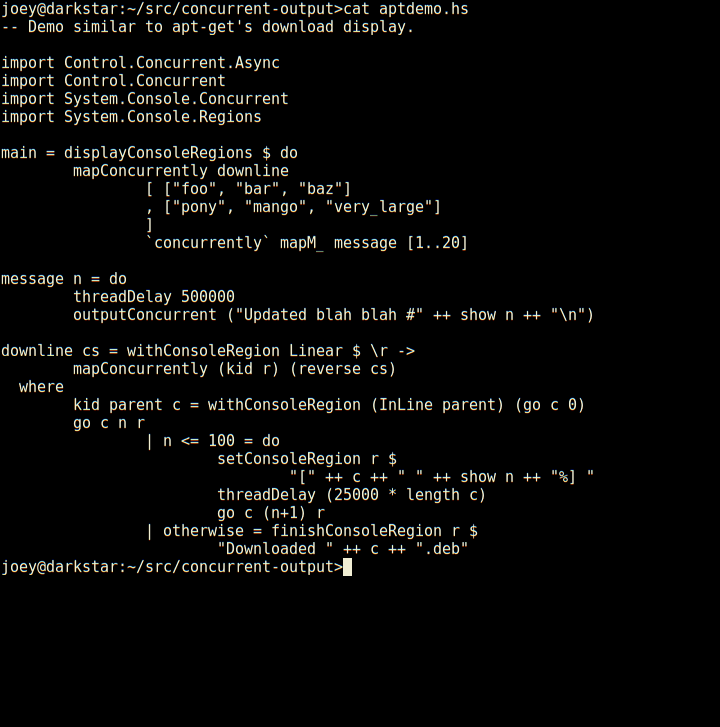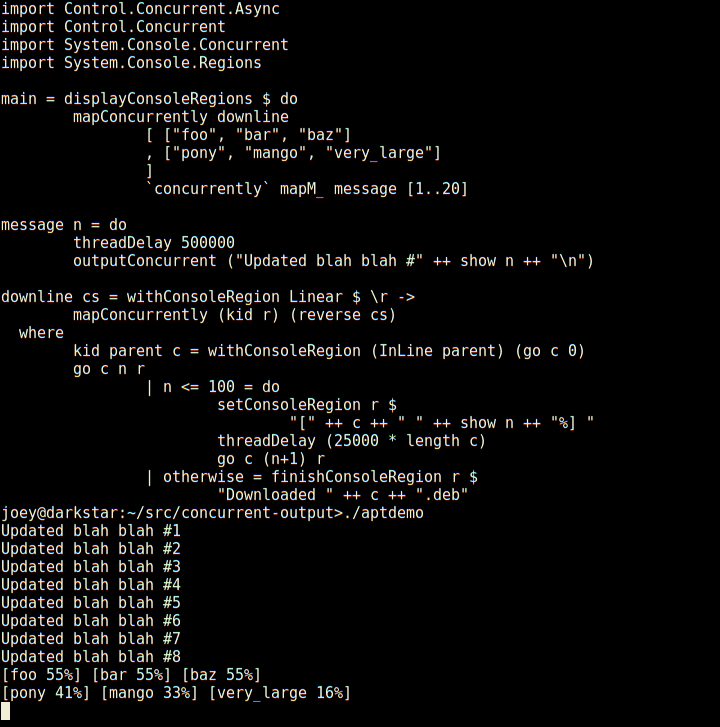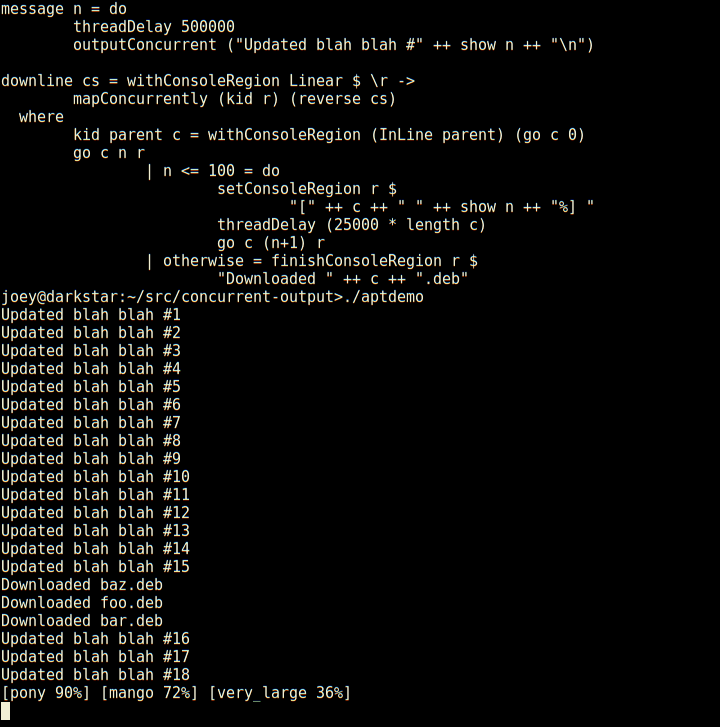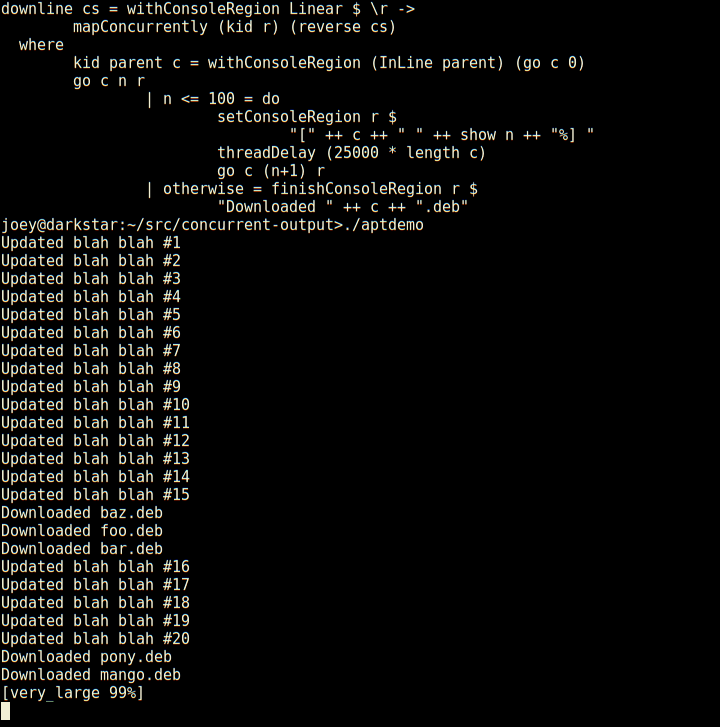
Not only does it have regions which are individual lines of the screen, but those can have sub-regions within them as seen here (and so on).
And, log-type messages automatically scroll up above the regions.
External programs run by createProcessConcurrent will automatically
get their output/errors displayed there, too.
What I'm working on now is support for multiline regions, which automatically grow/shrink to fit what's placed in them. The hard part, which I'm putting the finishing touches on, is to accurately work out how large a region is before displaying it, in order to lay it out. Requires parsing ANSI codes amoung other things.
STM rules
There's so much concurrency, with complicated interrelated data being updated by different threads, that I couldn't have possibly built this without Software Transactional Memory.
Rather than a nightmare of locks behind locks behind locks, the result is so well behaved that I'm confident that anyone who needs more control over the region layout, or wants to do funky things can dive into to the STM interface and update the data structures, and nothing will ever deadlock or be inconsistent, and as soon as an update completes, it'll display on-screen.
An example of how powerful and beuatiful STM is, here's how the main display thread determines when it needs to refresh the display:
data DisplayChange
= BufferChange [(StdHandle, OutputBuffer)]
| RegionChange RegionSnapshot
| TerminalResize (Maybe Width)
| EndSignal ()
...
change <- atomically $
(RegionChange <$> regionWaiter origsnapshot)
`orElse`
(RegionChange <$> regionListWaiter origsnapshot)
`orElse`
(BufferChange <$> outputBufferWaiterSTM waitCompleteLines)
`orElse`
(TerminalResize <$> waitwidthchange)
`orElse`
(EndSignal <$> waitTSem endsignal)
case change of
RegionChange snapshot -> do
...
BufferChange buffers -> do
...
TerminalResize width -> do
...
So, it composes all these STM actions that can wait on various kinds of changes, to get one big action, that waits for all of the above, and builds up a nice sum type to represent what's changed.
Another example is that the whole support for sub-regions only involved adding 30 lines of code, all of it using STM, and it worked 100% the first time.
Available in concurrent-output 1.1.0.