I've spent about 100 hours of work over the past month to make sure git-annex can build without dependencies that contain LLM generated code. At least so far.
https://git-annex.branchable.com/no_llm_code/
Needing to review a program's whole dependency tree on an ongoing basis is apparently what programming has come to?
I've found some real stinkers. Large LLM generated changes being reverted in the next release without any explanation. An incoherent 1489 line commit message with 10,000 lines of changes to a 26,000 LOC code base. A LLM prompt to copy code from another project that seems to have only avoided being copyright infringement due to luck.
I now have additional information about the quality of dependencies which will surely influence future decisions. As far as I can see, that's the only positive benefit of this work.
I realize that I am probably trying to hold back the tide at this point. That appears to be why Software Freedom Conservancy punted, and I doubt that the FSF will do any better.
As these dominos fall, I am reconsidering my participation in these communities. But I continue my work and support my users.
It may seem easy to prompt a LLM with
Add fourmolu config and restyled
neat
format a module
And commit the result and call yourself a 10xer. But please consider the broader impact of your actions. (In the above case, that project lost my further collaboration on it.)
No matter that the hype cycle wants you to think, the renewable energy transition is the biggest thing happening in tech and it's happening faster and faster. Despite being neck deep in it personally with offgrid solar projects, most recently solar hot water, increasingly it becomes clear I'm watching from the sidelines.
In Australia, everyone gets 24 kwh of free daytime electric power now. That's without installing any solar panels of their own, the grid just has that much excess capacity. All it takes to save $thousands per year (and avoid emissions) is to schedule some big loads like the hot water heater and EV to charge during the day. To save more, drop in a home battery that charges for free and powers the home through the evening.
In Germany, a 2 kwh plug-in home battery costs $350 and the electric company will pay you $130 per year to plug it into your wall. There are similar offers throughout Europe.
In Cuba something something geopolitics, oil blockade, belt and road => suddenly 1GW of solar farms with another gigawatt on the way.
I'll soon visit South Carolina where with no subsidies whatsoever from a decidedly renewable-unfriendly government, it made sense for my dad's house to get a whole home battery and double the solar array. The resulting system will be able to power the well pump and probably also the whole geothermal HVAC system through the kind of month-long grid down events that happened in Hurricane Helene.
Myself, well, I've got a by modern standards small 4 kwh home battery that powers my house offgrid, and I've recently installed a heat pump hot water heater. That's after about a decade pondering what solution to use for solar hot water, to replace an aging and horrible propane instant water heater. I've in the past considered everything from evacuated tubes to special direct drive inverters to DC resistive MPTT dump loads. The solution turned out to be just a big enough solar array, and plugging in a 120v hot water heater that needs only 500 watts in heat pump mode. Plus a small amount of code to manage when it runs.
In the time I was thinking about that, economies of scale and tech improvements just wiped all those other possibilities off the map, it's not economical to install and maintain a separate evactuated tube heat collector when a pile of solar panels costs so little and when electric hot water has gotten more than 200% efficient.
I also recently completed my permanant EV charger installation, with a new inverter and conduit and proper wiring, and increased the car's charge rate to 2 kw. Eliminating the need to charge anywhere except at home except on road trips.
Coordinating when these two big loads run, to maximize solar production and ensure that the house battery is full at the end of the day was ... not hard at all actually? The car charger amps can be dialed up and down to match incoming solar power fairly well, and leave some room for the hot water heater. They both operate as more or less dump loads. More or less because neither one can be cycled on or off very fast (to avoid wear and tear on the car's contactor and the heat pump's compressor), so it makes sense to leave them on and skate through short cloudy sections of the day, as long as the house battery doesn't get too low.
How low is too low for the house battery? Depends on the time of day. The code it's currently using, which may get tweaked over winter:
-- When the battery is charged enough to run major loads that may prevent
-- charging it further.
--
-- This varies with the hour of day. Early in the day, the battery does not
-- need to be as full to be considered well charged, since there is
-- still plenty of time for it to charge up. Later in the day, with less
-- time to charge, it needs to be more full.
wellCharged :: Hour -> Percentage
wellCharged (Hour hour)
| hour < 9 = Percentage 90 -- night
| pmhour <= 0 = Percentage 50
| pmhour <= 1 = Percentage 60
| pmhour <= 2 = Percentage 70
| pmhour <= 3 = Percentage 80
| pmhour <= 4 = Percentage 90
| otherwise = Percentage 95
where
pmhour = hour - 12
More complicated is, what to do it there's solar power to run one or the other, but not both? This is starting to get into the territory of microgrids now, or of demand response programs, so there's a whole industry or three out there doing industry things geared at the kind of no-brainer solutions I mentioned earlier. From what I've gathered, all of them involve proprietary protocols and gear.
What I've done is to read the state of the hot water heater and car, and prioritize hot water over the car. Except, if the car is below 10% it urgently needs to charge.
And I found a really simple way to decide when to run the low-priority
load: Just check if the house battery's current charge will be considered
wellCharged in an hour. So if it's 2 pm, the battery needs to be 80%
charged to run the lower-priority load, and if it dips below that, that
load will turn off but the high-priority load will keep running down to 70%
battery.
Unfortunately, getting any information out of my hot water heater relies on a vendor API server that is often down on weekends, and reverse engineered the web page of my EVSE[1] to control it, to say nothing of the nightmare of getting the car's state of charge from The Cloud.
Anyway, I'm pleased with having easily tweakable code and how far I've taken this offgrid, and everything I've learned doing so, but like I said, I'm clearly observing from the sidelines over here while the most significant thing for all of us is going on over there. You might appreciate my code or method, but you'll eventually be plugging in a home battery or signing up for a free daytime power tarrif from your electric company, or having professionals install a whole home system for climate resiliance.
So my question is, where does free software fit into all this? There are things like Home Assistant that do productize the kind of thing I'm doing enough to be useful more widely. But still niche. Meanwhile there are inverters and batteries that phone home to China, and every consumer facing install is either "use this device" or "integrate these 3 proprietary devices".
I don't think focusing on these negatives is really useful though, I'm more trying to understand where all this is going and then maybe get out ahead of it in some useful way with free software. Your thoughts welcome.
[1] Obviously OpenEVSE exists, but it didn't meet my needs hardware wise. And I could set my EVSE to use an OCPP server but it was easier to do the screen scraping than find an appropriate one, and I have the feeling I would not appreciate learning any more about OCPP, in the same way I really don't want to know a lot about web browsers' tag soup mode.
This is somehow the featured website on https://earlyweblinks.com/ this week.
Read all about my web site here! https://earlyweblinks.com/site-of-the-week/joey-hess
Kind of reminds me of back in 1995 or so when my website would randomly end up picked by some best of the web list that I never heard of. The web is still a small place I guess.
Maybe I should join a web ring or something?
Per my policies, I need to ban every employee and contractor of Anthropic Inc from ever contributing code to any of my projects. Anyone have a list?
Any project that requires a Developer Certificate of Origin or similar should be doing this, because Anthropic is making tools that explicitly lie about the origin of patches to free software projects.
UNDERCOVER MODE — CRITICAL
You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. [...] Do not blow your cover.
NEVER include in commit messages or PR descriptions:
[...] The phrase 'Claude Code' or any mention that you are an AI
Co-Authored-By lines or any other attribution
-- via @vedolos
Snow coming. I'm tuned into the local 24 hour slop weather stream. AI generated, narrated, up to the minute radar and forecast graphics. People popping up on the live weather map with questions "snow soon?" (They pay for the privilege.) LLM generating reply that riffs on their name. Tuned to keep the urgency up, something is always happening somewhere, scanners are pulling the police reports, live webcam description models add verisimilitude to the description of the morning commute. Weather is happening.
In the subtext, climate change is happening. Weather is a growth industry. The guy up in Kentucky coal country who put this thing together is building an empire. He started as just another local news greenscreener. Dropped out and went twitch weather stream. Hyping up tornado days and dicy snow forecasts. Nowcasting, hyper individualized, interacting with chat. Now he's automated it all. On big days when he's getting real views, the bot breaks into his live streams, gives him a break.
Only a few thousand watching this morning yet. Perfect 2026 grade slop. Details never quite right, but close enough to keep on in the background all day. Nobody expects a perfect forecast after all, and it's fed from the National Weather Center discussion too. We still fund those guys? Why bother when a bot can do it?
He knows why he's big in these states, these rural areas. Understands the target audience. Airbrushed AI aesthetics are ok with them, receive no pushback. Flying more under the radar coastally, but weather is big there and getting bigger. The local weather will come for us all.

(Not fiction FYI.)
A year ago I installed a 4 kilowatt solar fence. I'm revisiting it this Sun Day, to share the design, now that I have prooved it out.
 |
Solar fencing manufacturers have some good simple designs, but it's hard to buy for a small installation. They are selling to utility scale solar mostly. And those are installed by driving metal beams into the ground, which requires heavy machinery.
Since I have experience with Ironridge rails for roof mount solar, I decided to adapt that system for a vertical mount. Which is something it was not designed for. I combined the Ironridge hardware with regular parts from the hardware store.
The cost of mounting solar panels nowadays is often higher than the cost of the panels. I hoped to match the cost, and I nearly did. The solar panels cost $100 each, and the fence cost $110 per solar panel. This fence was significantly cheaper than conventional ground mount arrays that I considered as alternatives, and made a better use of a difficult hillside location.
I used 7 foot long Ironridge XR-10 rails, which fit 2 solar panels per rail. (Longer rails would need a center post anyway, and the 7 foot long rails have cheaper shipping, since they do not need to be shipped freight.)
For the fence posts, I used regular 4x4" treated posts. 12 foot long, set in 3 foot deep post holes, with 3x 50 lb bags of concrete per hole and 6 inches of gravel on the bottom.
 |
To connect the Ironridge rails to the fence posts, I used the Ironridge LFT-03-M1 slotted L-foot bracket. Screwed into the post with a 5/8” x 3 inch hot-dipped galvanized lag screw. Since a treated post can react badly with an aluminum bracket, there needs to be some flashing between the post and bracket. I used Shurtape PW-100 tape for that. I see no sign of corrosion after 1 year.
The rest of the Ironridge system is a T-bolt that connects the rail to the L-foot (part BHW-SQ-02-A1), and Ironridge solar panel fasteners (UFO-CL-01-A1 and UFO-STP-40MM-M1). Also XR-10 end caps and wire clips.
Since the Ironridge hardware is not designed to hold a solar panel at a 90 degree angle, I was concerned that the panels might slide downward over time. To help prevent that, I added some additional support brackets under the bottom of the panels. So far, that does not seem to have been a problem though.
I installed Aptos 370 watt solar panels on the fence. They are bifacial, and while the posts block the back partially, there is still bifacial gain on cloudy days. I left enough space under the solar panels to be able to run a push mower under them.
 |
I put pairs of posts next to one-another, so each 7 foot segment of fence had its own 2 posts. This is the least elegant part of this design, but fitting 2 brackets next to one-another on a single post isn't feasible. I bolted the pairs of posts together with some spacers. A side benefit of doing it this way is that treated lumber can warp as it dries, and this prevented much twisting of the posts.
Using separate posts for each segment also means that the fence can traverse a hill easily. And it does not need to be perfectly straight. In fact, my fence has a 30 degree bend in the middle. This means it has both south facing and south-west facing panels, so can catch the light for longer during the day.
After building the fence, I noticed there was a slight bit of sway at the top, since 9 feet of wooden post is not entirely rigid. My worry was that a gusty wind could rattle the solar panels. While I did not actually observe that happening, I added some diagonal back bracing for peace of mind.
 |
Inspecting the fence today, I find no problems after the first year. I hope it will last 30 years, with the lifespan of the treated lumber being the likely determining factor.
As part of my larger (and still ongoing) ground mount solar install, the solar fence has consistently provided great power. The vertical orientation works well at latitude 36. It also turned out that the back of the fence was useful to hang conduit and wiring and solar equipment, and so it turned into the electrical backbone of my whole solar field. But that's another story..
solar fence parts list
| quantity | cost per unit | description |
|---|---|---|
| 10 | $27.89 | 7 foot Ironridge XR-10 rail |
| 12 | $20.18 | 12 foot treated 4x4 |
| 30 | $4.86 | Ironridge UFO-CL-01-A1 |
| 20 | $0.87 | Ironridge UFO-STP-40MM-M1 |
| 1 | $12.62 | Ironridge XR-10 end caps (20 pack) |
| 20 | $2.63 | Ironridge LFT-03-M1 |
| 20 | $1.69 | Ironridge BHW-SQ-02-A1 |
| 22 | $2.65 | 5/8” x 3 inch hot-dipped galvanized lag screw |
| 10 | $0.50 | 6” gravel per post |
| 30 | $6.91 | 50 lb bags of quickcrete |
| 1 | $15.00 | Shurtape PW-100 Corrosion Protection Pipe Wrap Tape |
| N/A | $30 | other bolts and hardware (approximate) |
$1100 total
(Does not include cost of panels, wiring, or electrical hardware.)
Eight months ago I came up my rocky driveway in an electric car, with the back full of solar panel mounting rails. I didn't know how I'd manage to keep it charged. I got the car earlier than planned, with my offgrid solar upgrade only beginning. There's no nearby EV charger, and winter was coming, less solar power every day. Still, it was the right time to take a leap to offgid EV life.
My existing 1 kilowatt solar array could charge the car only 5 miles on a good day. Here's my first try at charging the car offgrid:
 |
It was not worth charging the car that way, the house battery tended to get drained while doing that, and adding cycles to that battery is not desirable. So that was only a proof of concept, I knew I'd need to upgrade.
My goal with the upgrade was to charge the car directly from the sun, even when it was cloudy, using the house battery only to skate over brief darker periods (like a thunderstorm). By mid October, I had enough solar installed to do that (5 kilowatts).
|
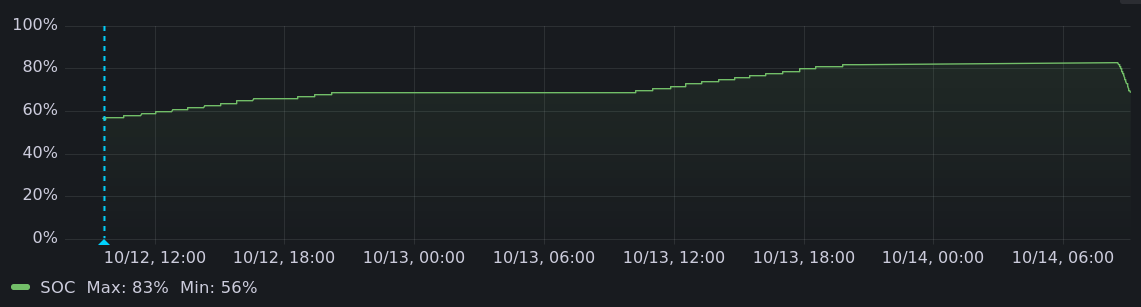 |
Using this, in 2 days I charged the car up from 57% to 82%, and took off on a celebratory road trip to Niagra Falls, where I charged the car from hydro power from a dam my grandfather had engineered.
When I got home, it was November. Days were getting ever shorter. My solar upgrade was only 1/3rd complete and could charge the car 30-some miles per day, but only on a good day, and weather was getting worse. I came back with a low state of charge (both car and me), and needed to get back to full in time for my Thanksgiving trip at the end of the month. I decided to limit my trips to town.
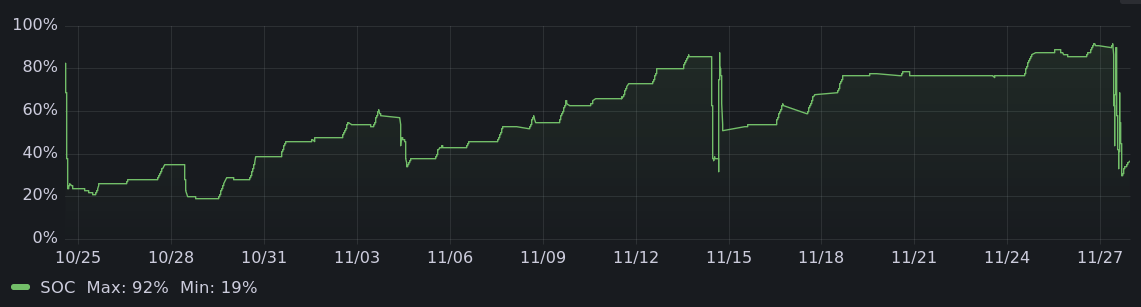 |
This kind of medium term planning about car travel was new to me. But not too unusual for offgrid living. You look at the weather forecast and make some rough plans, and get to feel connected to the natural world a bit more.
December is the real test for offgrid solar, and honestly this was a bit rough, with a road trip planned for the end of the month. I did the usual holiday stuff but otherwise holed up at home a bit more than I usually would. Charging was limited and the cold made it charge less efficiently.
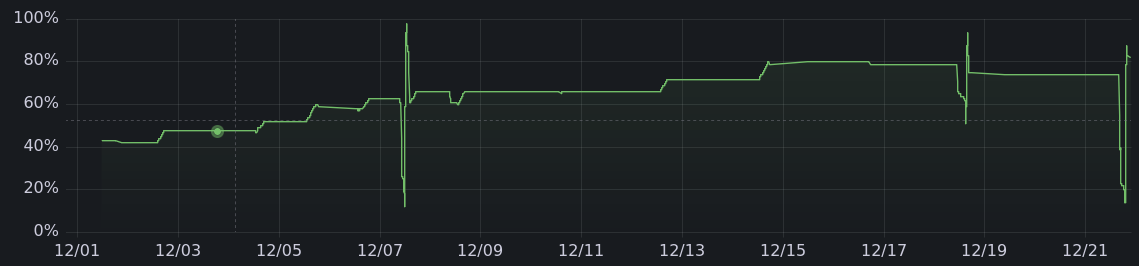 |
Still, I was busy installing more solar panels, and by winter solstice, was back to charging 30 miles on a good day.
Of course, from there out things improved. In January and February I was able to charge up easily enough for my usual trips despite the cold. By March the car was often getting full before I needed to go anywhere, and I was doing long round trips without bothering to fast charge along the way, coming home low, knowing even cloudy days would let it charge up enough.
That brings me up to today. The car is 80% full and heading up toward 100% for a long trip on Friday. Despite the sky being milky white today with no visible sun, there's plenty of power to absorb, and the car charger turned on at 11 am with the house battery already full.
My solar upgrade is only 2/3rds complete, and also I have not yet installed my inverter upgrade, so the car can only currenly charge at 9 amps despite much more solar power often being available. So I'm looking forward to how next December goes with my full planned solar array and faster charging.
But first, a summer where I expect the car will mostly be charged up and ready to go at all times, and the only car expense will be fast charging on road trips!
By the way, the code I've written to automate offgrid charging that runs only when there's enough solar power is here.
And here are the charging graphs for the other months. All told, it's charged 475 kwh offgrid, enough to drive more than 1500 miles.
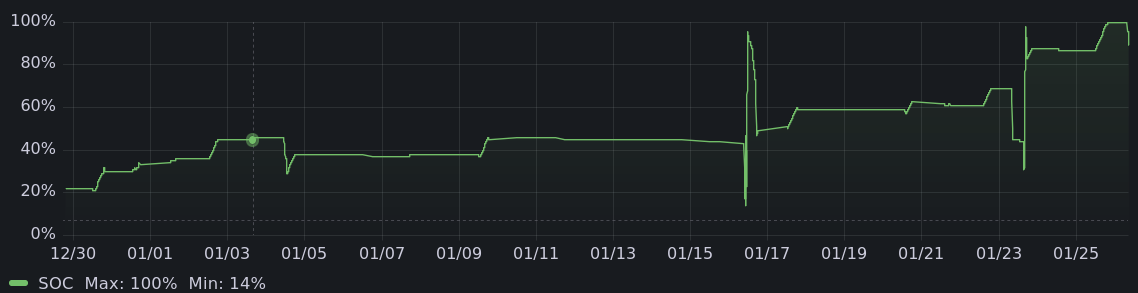 |
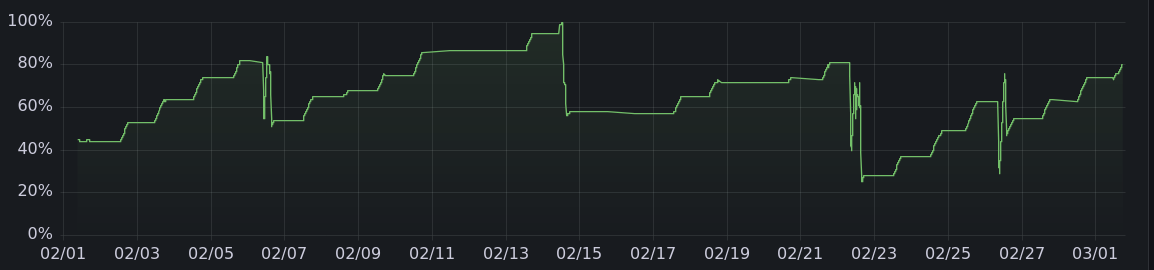 |
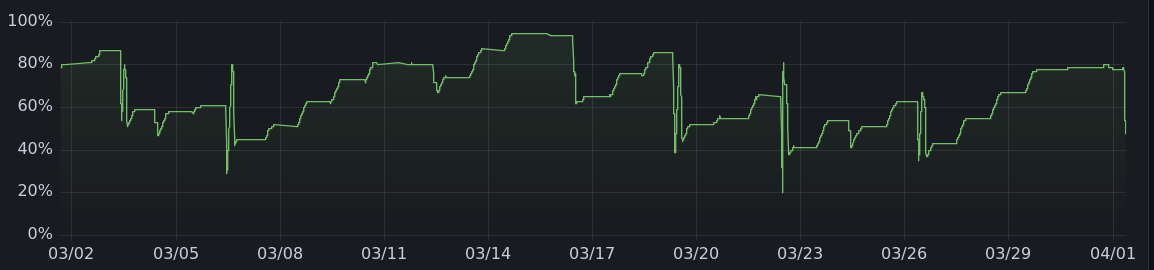 |
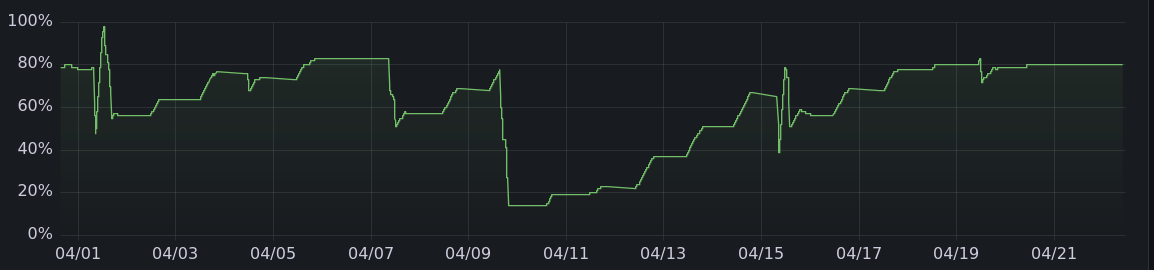 |
2026 update: After upgrading my inverter and running conduit, the car is finally charging at a faster rate of 16 amps, and the car typically charges 25% per day. That seems to be plenty for my needs.
So there are only 2 web browser engines, and it seems likely there will soon only be 1, and making a whole new web browser from the ground up is effectively impossible because the browsers vendors have weaponized web standards complexity against any newcomers. Maybe eventually someone will succeed and there will be 2 again. Best case. What a situation.
So throw out all the web standards. Make a browser that just runs WASM blobs, and gives them a surface to use, sorta like Wayland does. It has tabs, and a throbber, and urls, but no HTML, no javascript, no CSS. Just HTTP of WASM blobs.
This is where the web browser is going eventually anyway, except in the current line of evolution it will be WASM with all the web standards complexity baked in and reinforcing the current situation.
Would this be a mass of proprietary software? Have you looked at any corporate website's "source" lately? But what's important is that this would make it easy enough to build new browsers that they would stop being a point of control.
Want a browser that natively supports RSS? Poll the feeds, make a UI, download the WASM enclosures to view the posts. Want a browser that supports IPFS or gopher? Fork any browser and add it, the mantenance load will be minimal. Want to provide access to GPIO pins or something? Add an extension that can be accessed via the WASI component model. This would allow for so many things like that which won't and can't happen with the current market duopoly browser situation.
And as for your WASM web pages, well you can still use HTML if you like. Use the WASI component model to pull in a HTML engine. It doesn't need to support everything, just the parts of web standards that you want to use. Or you can do something entitely different in your WASM that is not HTML based at all but a better paradigm (oh hi Spritely or display postscript or gemini capsules or whatever).
Dual innovation sources or duopoly? I know which I'd prefer. This is not my project to build though.
I've been lucky to be able to spend twenty! five! years! developing free software and making a living on it, and this was a banner year for that career.
To start with, there was the Distribits conference. There's a big ecosystem of tools and projects that are based on git-annex, especially in scientific data management, and this was the first conference focused on that. Basically every talk involved git-annex in some way. It's been a while since I was at a conference where my software was in the center like that -- reminded me of Debconf days.
I gave a talk on how git-annex was probably basically feature complete. I have been very busy ever since adding new features to it, because in mapping out git-annex's feature set, I discovered new possibilities.
Meeting people and getting a better feel for the shape of that ecosytem, both technically and funding wise, led to several big developments in funding later in the year. Going into the year, I had an ongoing source of funding from several projects at Dartmouth that use git-annex, but after 10 years, some of that was winding up.
That all came together in my essentially writing a grant proposal to the OpenNeuro project at Stanford, to spend 6 months building out a whole constellation of features. The summer became a sprint to get it all done. Signficant amounts of very productive design work were done while swimming in the river. That was great.
(Somehow in there, I ended up onstage at FOSSY in Portland, in a keynote panel on Open Source and AI. This required developing a nuanced understanding of the mess of the OSI's Open Source AI definition, but I was mostly on the panel as the unqualified guy.)
Capping off the year, I have a new maintenance contract with Forschungszentrum Jülich. This covers the typical daily grind kind of tasks, like bug triage, keeping on top of security, release preparation, and updating dependencies, which is the kind of thing I've never been able to find dedicated funding for before.
A career in free software is a succession of hurdles. How to do something new and worthwhile? How to make any income while developing it at all? How to maintain your independant vision when working on it for hire? How to deal with burn-out? How to grow a project to be more than a one developer affair? And on and on.
How does a free software project keep paying the bills once it's feature complete? Maybe I am starting to get a glimpse of an answer.
I have been working all year on a solar upgrade aimed at December. Now here it is, midwinter, and my electric car is charging on a cloudy day from my offgrid solar fence.
I lived happily enough with 1 kilowatt of solar that I installed in 2017. Meanwhile, solar panel prices came down massively, incentives increased and everything came together: This was the year.
In the spring I started clearing forest trees that were leaning over the house, making both a firebreak and a solar field.
In June I picked up a pallet of panels in a box truck.
 |
In August I bought the EV and was able to charge it offgrid from my old solar system... a few miles per day on the most sunny days.
In September and October I built a solar fence, of my own design.
|
For the past several weeks I have been installing additional solar panels on ballasted ground mounts full of gravel. At this point I'm half way through installing my 30 panel upgrade.
The design goal of my 12 kilowatt system is to produce 1 kilowatt of power all day on a cloudy day in midwinter, which allows swapping between major loads (EV charger, hot water heater, etc) on a cloudy day and running everything on a sunny day. So the size of the battery bank doesn't matter much. Batteries are getting cheaper fast too, but they are a wear item, so it's better to oversize the solar system and minimize the battery.
A lot of this is nonstandard and experimental. And that makes sense with the price of solar panels. It costs more to mount solar panels now than the panels are worth. And non-ideal panel orientation isn't a problem when the system is massively overpaneled.
I'm hoping to finish up the install before the end of winter. I have more trees to clear, more ballasted ground mounts to install, and need to come up with something even more experimental for a half dozen or so panels. Using solar panels as mounts for solar panels? Hanging them from trees?
Soon the wan light will fade, time to head off to the solstice party to enjoy the long night, and a bonfire.
 |